

Overview
We conduct research that spans several areas of database systems such as information integration, data provenance, scheduling, stream processing, and data mining. Our main contributions impacted the theoretical and practical research in data provenance. We strive to develop solutions to emerging challenges in database systems such as tight integration of provenance support into database engines, provenance for distributed data processing paradigms, and provenance for sequences of database operations. For a list of our publications click here.
Projects
|
BART BART is an error-generation tool for data cleaning applications. Its purpose is to introduce errors into clean databases for the purpose of benchmarking data-repairing algorithms. |

|
|
Explanations beyond Provenance Explaining Query Results Beyond Provenance |
|
|
Big Provenance developing algorithms and systems for scaling provenance to Big Data dimensions. |
|
|
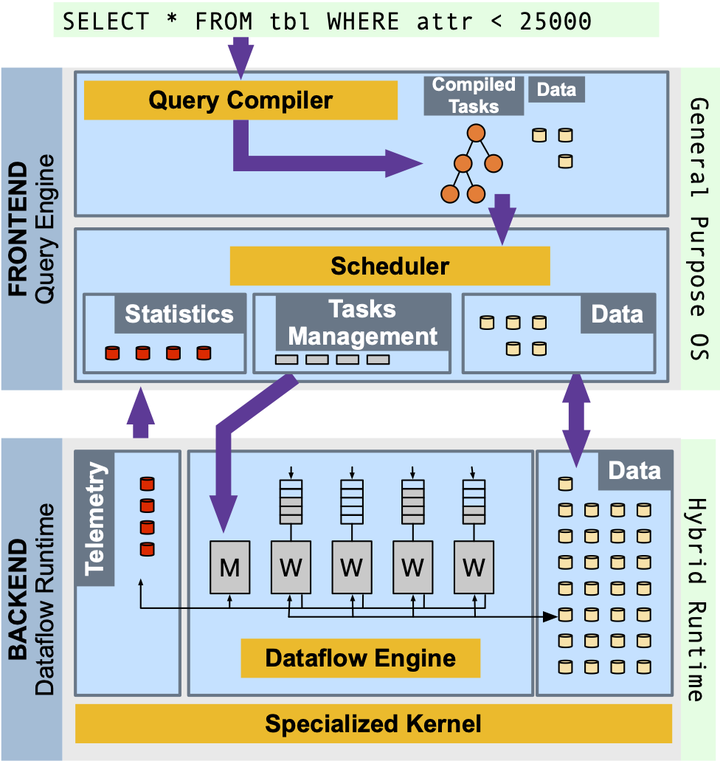
HCDF A Hybrid OS / Runtime for Task-based In-memory Query Processing |
|
|
GProM A database-independent middleware for computing the provenance of queries, updates, and transactions |

|
|
HRDBMS is a distributed database build from scratch that combines the best of traditional relational platforms with ideas from Big Data platforms. |
|
|
iBench A new, generic benchmark generator for data integration tasks. |
|
|
LDV LDV is a lightweight database virtualization system marrying OS and DB provenance. |

|
|
PUGS PUGS is a unified framework for capturing why and why-not provenance of Datalog queries with negation and for automatic generation of concise provenance summaries. |

|
|
Relevance-based Data Management We use provenance to determine what data is relevant for which task and then exploit this information to improve a wide range of data management tasks. |
|
|
Snapshot Semantics for Temporal Databases We conduct a principled investigation of temporal query semantics. Our current focus is a provably correct approach for snapshot semantics for sets, bags, and beyond. |
|
|
Uncertainty-Annotated Databases In this project, we develop a practical, yet principled, approach for managing uncertain data. |
|
|
Provenace for Updates and Transactions In this project, we study provenance models for update and transactions and their implementation through reenactment, a declarative replay technique which utilizes audit logs and temporal database technologies. |
|
|
Vizier A framework for user-friendly and effective data curation. |
Past Projects
|
Ariadne Computing fine-grained Provenance for Data Streams using Operator Instrumentation |

|
|
Native Database Provenance In this project we study how to integrate provenance techniques with a database core to improve various aspects of provenance managements including performance and storage requirements. |
|
|
Oshiya Declarative modelling and implementation of domain specific scheduling protocols. |
|
|
Perm Efficient Provenance Support for Relational Databases |

|
|
TRAMP Understanding the Behavior of Schema Mappings though Provenance and Meta-querying |

|
|
Vagabond Automatic generation of explanations for data exchange errors. |

|
Sponsors
We would like to thank the following sponsors for their support:

|
National Science Foundation |

|
Illinois Instituts of Technology |
Oracle External Research Office (ERO) |
Collaborators
We are grateful to our awesome current and past collaborators!- Aaron Huber - SUNY Buffalo
- Alex Rasin - DePaul University
- Alexandra Meliou - University of Massachusetts, Amherst
- Amir Gilad - Duke University
- Anton Dignös - Free University of Bozen/Bolzano
- Atri Rudra - SUNY Buffalo
- Babak Salimi - University of California, San Diego
- Bertram Ludäscher - UIUC
- Carl-Christian Kanne - Platfora
- Carlos Bautista - NYU
- Christian Tilgner
- Danica Porobic - Oracle
- Dieter Gawlick - Oracle
- Donatello Santoro - Università della Basilicata
- Eric Houston
- Fatemeh Nargesian - University of Rochester
- Giansalvatore Mecca - Università della Basilicata
- Gustavo Alonso - ETH Zurich
- Heiko Müller - NYU
- Ioan Raicu - Illinois Institute of Technology
- James Wagner - DePaul University
- Jiang Du
- Jiongli Zhu - University of California, San Diego
- Johann Gamper - Free University of Bozen/Bolzano
- Juliana Freire - NYU
- Kenny Gross - Oracle
- Kyle Hale - Illinois Institute of Technology
- Kyumars Sheyk Esmaili
- Laura Haas - UMass Amherst
- Melanie Herschel - University of Stuttgart
- Michael Brachmann - Breadcrumb Analytics
- Michael H. Böhlen - University of Zurich
- Nesime Tatbul - Intel Labs
- Oliver Kennedy - SUNY Buffalo
- Paolo Papotti - Eurecom
- Patricia C. Arocena - TD
- Periklis Andritsos - University of Toronto
- Peter M. Fischer - University of Augsburg
- Poonam Kumari - SUNY Buffalo
- Radu Ciucanu - Université d'Orléans
- Ralf Diestelkämper - University of Stuttgart
- Remi Rampin - NYU
- Renée J. Miller - Northeastern University
- Romila Pradhan
- Sonia Castelo - NYU
- Sudeepa Roy - Duke University
- Sven Köhler - Google
- Tanu Malik - DePaul University
- Vasudha Krishnaswamy - Oracle
- Venkatesh Radhakrishnan
- William Spoth - SUNY Buffalo
- Ying Yang - Oracle
- Zhen Hua Liu - Oracle
- Zhengjie Miao - Duke University