

Vagabond

The Vagabond system uses a novel holistic approach to help users to understand and debug data exchange scenarios. Developing such a scenario is a complex and labor-intensive process where errors are often only revealed in the target instance produced as the result of this process. This makes it very hard to debug such scenarios, especially for non-power users. Vagabond aides a user in debugging by automatically generating possible explanations for target instance errors identified by the user.
For large schemata, the multi-step process of generating a schema mapping is error-prone. Often, errors become apparent only in the generated target instance. For example, a user may recognize that some attribute values in the target instance are incorrect. Tracing errors is time-consuming and complex, because of the many possible sources of errors: data, correspondences, schema mappings, or transformations. Previous work focused on aiding the user in debugging by (1) providing additional information, such as provenance, and better query language support for schema mappings (TRAMP, MXQL, Spider) or (2) through programming language style debugging like breakpoints (Spider). These approaches have in common that they are more tailored for power users - they require the user to understand what possible sources of errors are and rely on her to guide the debugging process accordingly. In contrast to these approaches, Vagabond automatically generates and ranks explanations for errors in a data exchange setting based on user provided input about which parts of a generated target instance are erroneous. The rationale behind this approach is that (1) even inexperienced users are able to recognize instance errors, and (2) for both inexperienced and power users it is much harder to come up with explanations than to verify if a given explanation is correct.
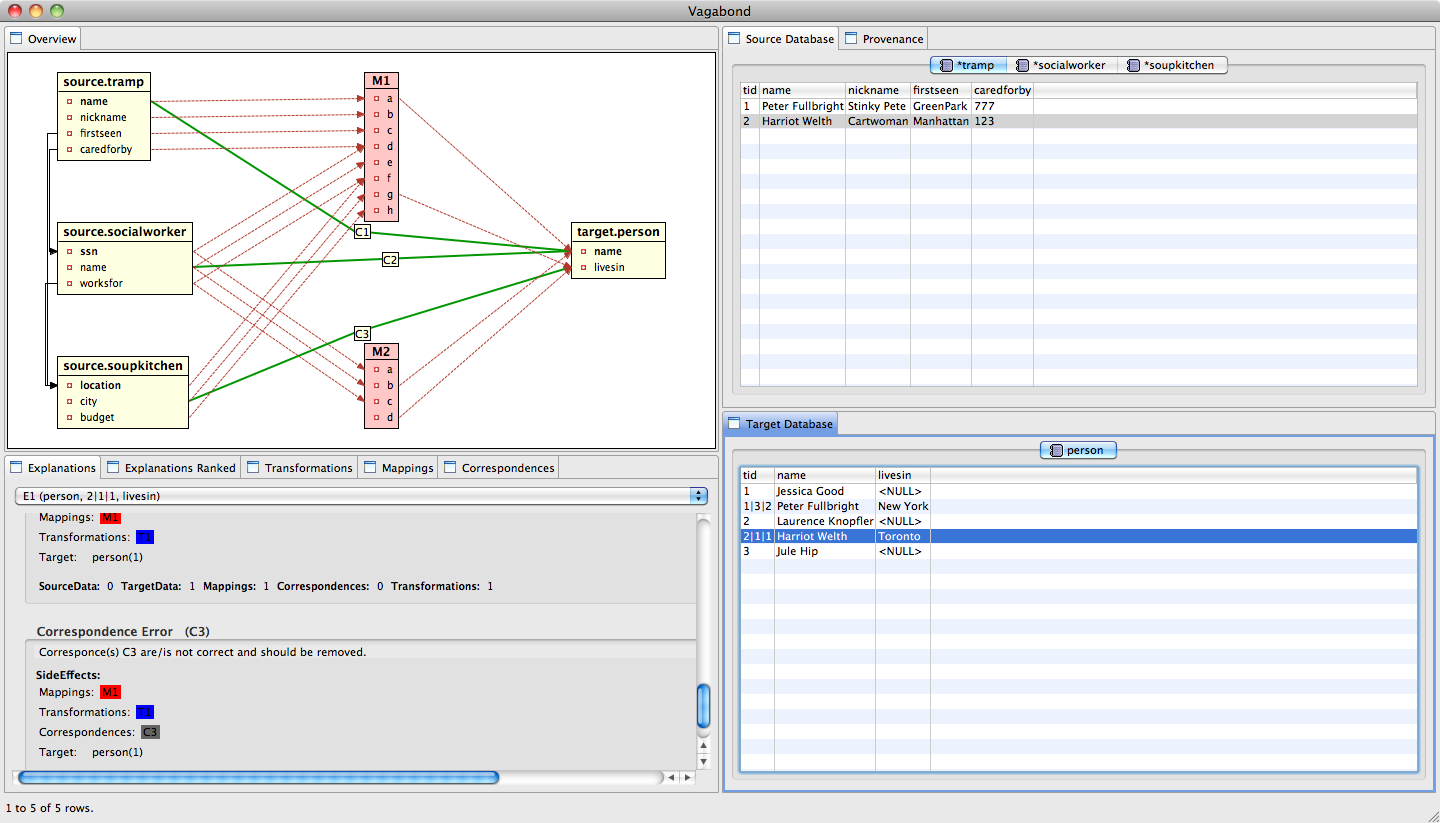
The explanation generation of Vagabond builds on the facilities provided by TRAMP to generate and query data, various kinds of provenance, and mapping information. We consider data, correspondences, mappings, and transformations as potential causes of errors. For instance, a possible explanation for incorrect values in a target relation is that the source data where this information has been copied from is erroneous. Data provenance is used to identify this part of the source data. For each generated explanation we compute which mapping scenario elements and parts of the instance would be affected by the explanation (called the side-effects). The user can mark an explanation as correct. This will cause the side-effects of this explanation to be considered as additional errors, thus avoiding the need to mark all target instance errors to debug a data exchange scenario. To present more likely explanations first, we rank them on the number of side-effects they imply. The explanation generation is complemented with visualization of provenance and mapping information. Vagabond provides an easy-to-use GUI for navigating through this information.
Collaborators
- Gustavo Alonso - ETH Zurich
- Laura Haas - UMass Amherst
- Renée J. Miller - Northeastern University
Publications
-
Automatic Generation and Ranking of Explanations for Mapping Errors
Seokki Lee, Zhen Wang, Boris Glavic and Renée J. Miller
Technical Report #IIT/CS-DB-2015-01
Illinois Institute of Technology.details@techreport{LW15, author = {Lee, Seokki and Wang, Zhen and Glavic, Boris and Miller, Ren\'{e}e J.}, date-modified = {2015-08-08 08:34:28 +0000}, institution = {Illinois Institute of Technology}, keywords = {Provenance; Vagabond; Data Exchange}, number = {IIT/CS-DB-2015-01}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/LW15.pdf}, projects = {Vagabond}, title = {Automatic Generation and Ranking of Explanations for Mapping Errors}, venueshort = {Techreport}, year = {2015}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/LW15.pdf} }
-
Computing Candidate Keys Of Relational Operators For Optimizing Rewrite-Based Provenance Computation
Andrea Cornudella
Illinois Institute of Technology.details@mastersthesis{A15, author = {Cornudella, Andrea}, keywords = {Provenance; Vagabond; Data Exchange}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/A15.pdf}, projects = {Vagabond}, school = {Illinois Institute of Technology}, title = {{Computing Candidate Keys Of Relational Operators For Optimizing Rewrite-Based Provenance Computation}}, venueshort = {Master Thesis}, year = {2015}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/A15.pdf} }
-
Efficient Scoring and Ranking of Explanation for Data Exchange Errors in Vagabond
Zhen Wang
Illinois Institute of Technology.details@mastersthesis{W14, author = {Wang, Zhen}, date-added = {2014-05-21 18:55:49 +0000}, date-modified = {2014-05-21 18:55:49 +0000}, keywords = {Provenance; Vagabond; Data Exchange}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/Z14.pdf}, projects = {Vagabond}, school = {Illinois Institute of Technology}, title = {{Efficient Scoring and Ranking of Explanation for Data Exchange Errors in Vagabond}}, venueshort = {Master Thesis}, year = {2014}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/Z14.pdf} }
-
Debugging Data Exchange with Vagabond
Boris Glavic, Jiang Du, Renée J. Miller, Gustavo Alonso and Laura M. Haas
Proceedings of the VLDB Endowment (Demonstration Track). 4, 12 (2011) , 1383–1386.details@article{GD11, author = {Glavic, Boris and Du, Jiang and Miller, Ren\'{e}e J. and Alonso, Gustavo and Haas, Laura M.}, date-added = {2012-12-14 18:55:49 +0000}, date-modified = {2012-12-18 17:17:34 +0000}, journal = {Proceedings of the VLDB Endowment (Demonstration Track)}, keywords = {Provenance; Vagabond; Data Exchange}, number = {12}, pages = {1383-1386}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GD11.pdf}, projects = {Vagabond}, title = {{Debugging Data Exchange with Vagabond}}, venueshort = {PVLDB}, volume = {4}, year = {2011}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GD11.pdf} }In this paper, we present Vagabond, a system that uses a novel holistic approach to help users to understand and debug data exchange scenarios. Developing such a scenario is a complex and labor-intensive process where errors are often only revealed in the target instance produced as the result of this process. This makes it very hard to debug such scenarios, especially for non-power users. Vagabond aides a user in debugging by automatically generating possible explanations for target instance errors identified by the user.