

Perm

Data provenance is information about the origin and creation process of data. The provenance of data item, an atomic piece of data, may include source and intermediate data as well as the transformations involved in producing a concrete data item. In the context of relational databases, the source and intermediate data items are relations, tuples and attribute values. The transformations are SQL queries and/or functions on the relational data items. Provenance is of immense importance in a variety of application domains. It can be used to debug queries and clean data in data warehouses, to understand and correct complex data integration transformations, and to understand the value of data in curated databases. Provenance generation has also been used as supporting technology for exchanging updates between heterogeneous databases and in modeling uncertainty in databases. While provenance has many applications, these applications often place very high requirements on a provenance management system to be useful in practice.
Unfortunately, few practical relational provenance systems exist and most support only small subsets of SQL. To address this gap, we have developed Perm (Provenance Extension of the Relational Model), a DBMS that generates different types of provenance information for complex SQL queries (e.g., we support nested and correlated subqueries and aggregation). The two key ideas behind Perm are representing data and its provenance together in a single relation and relying on query rewrites to generate this representation. Through this, Perm supports fully integrated, on-demand provenance generation and querying using SQL. Since Perm rewrites a query requesting provenance into a regular SQL query and generates easily optimizable SQL code, its performance greatly benefits from the query optimization techniques provided by the underlying DBMS. We have released the system as open source on https://github.com/IITDBGroup/perm.
Perm represents provenance information as relations that are generated and queried on-demand using standard SQL queries. If the users requests one of the provenance types supported by Perm for a query q using the SQL-PLE language extension, the system transforms q into a query that returns the provenance of q in addition to the regular results of q. Perm supports the provenance shown in the table below.
As an example for the type of provenance generated by Perm consider the query and database shown below (For convenience, we shown an identifier for each tuple at the left of the tuple). This query joins a Customer with an Address relation to return customers names and associated cities. Each tuple in the result of this query is produced by joining a tuple from relation Customer with a tuple from relation Address. For example, tuple is derived from tuples and . If we use Perm to generate the provenance of this query, the result would be the relation shown below. Each tuple in this relation is a tuple from the original query result augmented with tuples from its provenance. For example, is paired with and and is paired with and .
Features
An overview of the main features of Perm are:
- Support for different types of provenance:
- Why-Provenance: Perm-Influence Contribution Semantics (PI-CS)
- Where-Provenance: Copy Contribution Semantics (C-CS), Where-Provenance (Buneman et al.)
- How-Provenance: Provenance Polynomials
- Transformation Provenance
- Provenance generation for complex SQL Queries:
- Select-Project-Join (SPJ)
- Aggregation
- Set Operations
- Nested and Correlated Subqueries
- Relational Representation of Provenance
- SQL Language Extension (SQL-PLE) for On-demand Provenance Generation
- Query Rewrite Based Computation of Provenance inside the DBMS
Relational Provenance Representation
Perm represents the provenance of a query q as a single relation that contains both the original query results of q and its provenance. Provenance information is attached to a query result tuple by extending the tuple with additional attributes that are used to store provenance information. Regular result tuples are duplicated if necessary to “fit in” their complete provenance. PI-CS and C-CS, the two data provenance semantics developed for Perm, represent provenance as so-called witness lists. A witness-list is a list of input tuples to a query that were used together to derive an output tuple; one from each input relation of the query (leaves of the algebra tree) or the special value which indicates that no tuple from the relation at this position contributed. The relational representation of PI-CS and C-CS appends all attributes from the relations accessed by the query to the query’s result schema. The additional attributes in the provenance representation are used to extend a result tuple with all tuples from one of its witness lists. Thus, tuples with more than one witness list in their provenance are duplicated and each duplicate is paired with the relational encoding of one witness list. To distinguish between regular result attributes and provenance attributes, the later are identified by a prefix and the name of the relation they are derived from (adding a distinguishing identifier for relations that are accessed more than once by the query). The special value used in witness lists is modeled as NULL values in the representation.
Consider the query and example database shown above. The PI-CS provenance is shown below. Provenance attribute names for PI-CS are given in a separate table to simplify the example. Tuple in the result of the query was derived by joining tuple with tuples and . Thus, the PI-CS provenance of tuple consists of two witness lists and . These are represented as two tuples in the relational representation by duplicating and pairing each duplicate with the tuples from one of the witness lists.
The figure on the right shows the transformation provenance for tuples and . Tuple is derived from the left input of the union without any influence from its right input. Therefore, the right input of the union is enclosed in a NOT tag in the transformations provenance of . Similarly, tuple was produced by the right branch of the union. Thus, the left branch is enclosed in NOT.
Query Rewrite Techniques
The research underlying Perm has demonstrated that SQL is powerful enough to express the computation of provenance for a large subset of queries expressible in SQL. The approach supports aggregations, set operations, nested or correlated subqueries, and user-defined functions. We do not support non-deterministic functions that return different results for the same input in the scope of one query. For example, a random number generator is a non-deterministic function.
Requesting the provenance of a query through the system's SQL extensions (see below) instructs Perm to rewrite into a standard SQL query that returns one type of provenance for using the provenance representation introduced above. The query rewrites for each provenance type were developed following the process shown in the Figure to the right. (1) We state a provenance type's semantics as a declarative definition and define a relational representation. This approach was chosen because correctness criteria one would intuitively expect to hold for provenance are easily stated declaratively. For instance, for data provenance, the provenance of a tuple from the result of a query should contain sufficient information to produce the tuple . (2) From the declarative definition we derive algebraic rewrites which transform a query into a provenance-generating query and prove their correctness. (3) A canonical translation is applied to translate the algebraic rewrites into SQL rewrites.
The seamless integration of provenance generation as an SQL language feature has many advantages. We can provide full SQL query support for provenance information. The rewrite rules are unaware of how the provenance attributes of their input were produced. Thus, they can be used to propagate provenance information that was created manually or by another provenance management system. A query over provenance data is implemented as a regular SQL query with a subquery that implements the provenance generation. Thus, we fully utilize the DBMS optimizer to speed up provenance computation by, e.g., pushing selections and projections applied by a query into the provenance generation. Since optimizing provenance generation is still in its infancy, this is a feasible approach for efficient provenance generation and querying (e.g., we can efficiently compute the PI-CS provenance of the TCP-H benchmark queries for a 1GB TCP-H instance).
SQL Language Extension (SQL-PLE)
The provenance language extension (SQL-PLE) of Perm enriches SQL with additional keywords to request provenance, control how far to trace provenance, and to inform the system about existing provenance information.
The query shown above runs over the schema introduced in the section about provenance representation. This query returns the months during which customers with at least two credit cards exceeded their credit limit on some card. To understand from which inputs of the result tuple (Joe,Feb) is derived, a user needs access to the data provenance of the query and the ability to query this information. For example, a user may be interested in knowing if some of these over-drafts are caused by suspiciously low credit card limits. This question can be answered by running a query over the provenance of to retrieve tuples in the result of that depend on credit card tuples with low limit values (i.e., these credit card tuples belong to the data provenance of the tuples to be returned). Alternatively, if the user is interested in where the name attribute values in the query result have been copied from, a different type of provenance is needed that tracks copying of information instead of which inputs caused a tuple to appear in the query result.
The keyword PROVENANCE is employed in the SELECT clause of a query to instruct Perm to compute the provenance of . An optional ON CONTRIBUTION modifier is used to choose the provenance type that is produced (PI-CS is the default). For example, the query below returns the PI-CS provenance of the query presented above.
Note that all original SQL features provided by PostgreSQL are not affected by the language extension, and even more important, they can be used in combination with provenance computation. Given the provenance representation of Perm this enables complex queries that filter provenance based on properties of the input tuples in the provenance and/or the result tuples of the query.
Assume the user expected the running example query to return less credit over-drafts. Her assumption is that some over-drafts are caused by credit card limits which have been recorded too low. The user runs the following query to determine which over-drafts are caused by (have tuples in their provenance with) suspiciously low credit card limits (say $500):
The default behaviour is to generate the provenance of a complete query by tracing which tuples in the query's input affected which tuples in the query result. Perm also supports limiting the provenance generation to parts of a query to trace the effect of intermediate query results instead of the input relations. The keyword BASERELATION is appended to an item in the FROM clause to limit how far back the provenance is computed.
Retrieving the full provenance of the running example query may return a large number of tuples, because each aggregated monthly amount (subquery monthly) can depend on a large number of individual purchases. Questions like the one from the initial example can be answered without information about the influence of each individual purchase tuple. The user can mark the subquery monthly with the BASERELATION keyword to only investigate the effect of the aggregated monthly amounts.
Perm can handle existing provenance information that was not produced by the system itself as long as (1) it is stored in additional attributes of tuples following the representation used by Perm and (2) the system is made aware of which attributes store provenance information (by appending the keyword PROVENANCE followed by a list of attribute names to the FROM-clause item).
The imports relation from the running example stores from which data sources each purchase tuple is imported. This is a kind of provenance information for the purchase relation. Joining the imports relation with the purchase relation and using the PROVENANCE keyword in the FROM clause, the user makes Perm aware of the existence of the additional provenance data. The system will treat this provenance in the same way as provenance generated by the system itself. The modified example query is shown below.
Implementation
Perm is implemented as a modified PostgreSQL engine, extending its SQL dialect with provenance features. Provenance generation in Perm is light-weight and lazy: no provenance is generated unless explicitly requested. Thus, if the provenance features of Perm are not used, the system behaves like a normal Postgres server - clients will observe no overhead in runtime or storage space. The figure below shows the architecture of the system. The parser and analyzer module of PostgreSQL (extended to recognize SQL-PLE) parse incoming SQL queries and transform them into an internal tree representation. The output of the analyzer module is passed to the Perm rewrite module. This module implements the query rewrite rules as transformations on query trees. The rewritten query tree produced by the Perm module is handed over to the original Postgres optimizer. From the optimizer’s point of view the input it retrieves is a regular SQL query.
Perm Browser
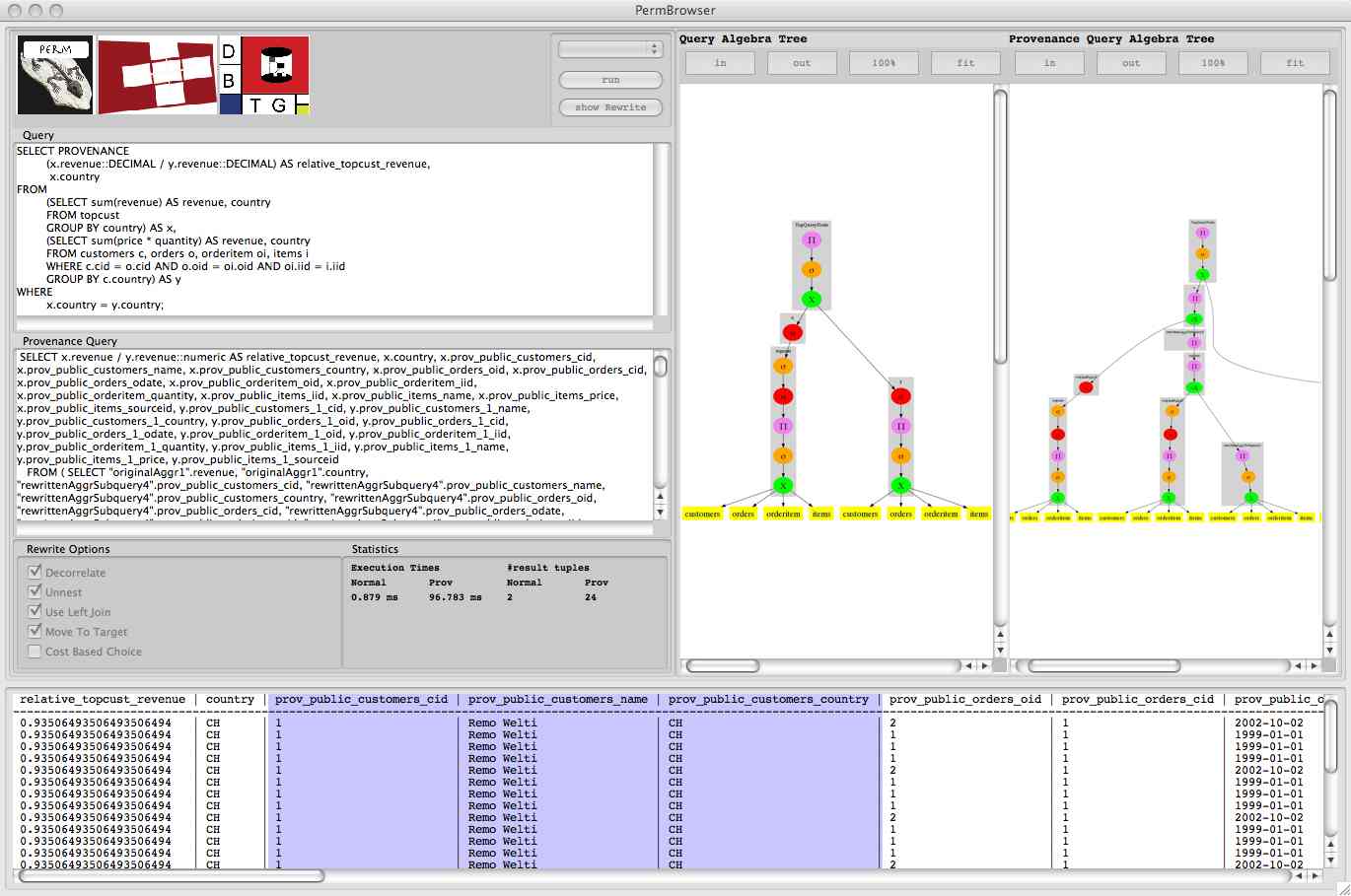
The Perm Browser is a client application that was developed for demonstration purposes. The browser is written in Java and connects to a Perm server instance though JDBC. Given an input query from the user, the browser will show the results of the query, the SQL text for the rewritten query, algebra trees for both the original and rewritten query, and statistics about the execution of the original and rewritten query (e.g., number of result tuples, execution time, ...). A screenshot of the application is shown below.
Collaborators
- Gustavo Alonso - ETH Zurich
- Renée J. Miller - Northeastern University
Publications
-
Using SQL for Efficient Generation and Querying of Provenance Information
Boris Glavic, Renée J. Miller and Gustavo Alonso
In search of elegance in the theory and practice of computation: a Festschrift in honour of Peter Buneman. (2013) , 291–320.details@article{GM13, author = {Glavic, Boris and Miller, Ren{\'e}e J. and Alonso, Gustavo}, date-added = {2013-07-09 22:54:03 +0000}, date-modified = {2013-08-22 22:56:39 +0000}, journal = {{In search of elegance in the theory and practice of computation: a Festschrift in honour of Peter Buneman}}, keywords = {Perm; Provenance}, pages = {291-320}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GM13.pdf}, projects = {Perm}, title = {Using SQL for Efficient Generation and Querying of Provenance Information}, venueshort = {Festschrift Peter Buneman}, year = {2013}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GM13.pdf} }In applications such as data warehousing or data exchange, the ability to efficiently generate and query provenance information is crucial to understand the origin of data. In this chapter, we review some of the main contributions of Perm, a DBMS that generates different types of provenance information for complex SQL queries (including nested and correlated subqueries and aggregation). The two key ideas behind Perm are representing data and its provenance together in a single relation and relying on query rewrites to generate this representation. Through this, Perm supports fully integrated, on-demand provenance generation and querying using SQL. Since Perm rewrites a query requesting provenance into a regular SQL query and generates easily optimizable SQL code, its performance greatly benefits from the query optimization techniques provided by the underlying DBMS.
-
Perm: Efficient Provenance Support for Relational Databases
Boris Glavic
University of Zurich.details@phdthesis{G10a, author = {Glavic, Boris}, date-added = {2012-12-14 18:55:49 +0000}, date-modified = {2012-12-14 18:55:49 +0000}, keywords = {Provenance; Perm}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/G10a.pdf}, projects = {Perm}, school = {University of Zurich}, title = {{Perm: Efficient Provenance Support for Relational Databases}}, venueshort = {PhD Thesis}, year = {2010}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/G10a.pdf} }In many application areas like scientific computing, data-warehousing, and data integration detailed information about the origin of data is required. This kind of information is often referred to as data provenance. The provenance of a piece of data, a so-called data item, includes information about the source data from which it is derived and the transformations that lead to its creation and current representation. In the context of relational databases, provenance has been studied both from a theoretical and algorithmic perspective. Yet, in spite of the advances made, there are very few practical systems available that support generating, querying and storing provenance information (We refer to such systems as provenance management systems or PMS). These systems support only a subset of SQL, a severe limitation in practice since most of the application domains that benefit from provenance information use complex queries. Such queries typically involve nested sub-queries, aggregation and/or user defined functions. Without support for these constructs, a provenance management system is of limited use. Furthermore, existing approaches use different data models to represent provenance and the data for which provenance is computed (normal data). This has the intrinsic disadvantage that a new query language has to be developed for querying provenance information. Naturally, such a query language is not as powerful and mature as, e.g., SQL. In this thesis we present Perm, a novel relational provenance management system that addresses the shortcoming of existing approaches discussed above. The underlying idea of Perm is to represent provenance information as standard relations and to generate and query it using standard SQL queries; ”Use SQL to compute and query the provenance of SQL queries”. Perm is implemented on top of PostgreSQL extending its SQL dialect with provenance features that are implemented as query rewrites. This approach enables the system to take full benefit from the advanced query optimizer of PostgreSQL and provide full SQL query support for provenance information. Several important steps were necessary to realize our vision of a ”purely relational” provenance management system that is capable of generating provenance information for complex SQL queries. We developed new notions of provenance that handle SQL constructs not covered by the standard definitions of provenance. Based on these provenance definitions rewrite rules for relational algebra expressions are defined for transforming an algebra expression q into an algebra expression that computes the provenance of q (These rewrites rules are proven to produce correct and complete results). The implementation of Perm, based on this solid theoretical foundation, applies a variety of novel optimization techniques that reduce the cost of some intrinsically expensive provenance operations. By applying the Perm system to schema mapping debugging - a prominent use case for provenance - and extensive performance measurements we confirm the feasibility of our approach and the superiority of Perm over alternative approaches.
-
The Perm Provenance Management System in Action
Boris Glavic and Gustavo Alonso
Proceedings of the 35th ACM SIGMOD International Conference on Management of Data (Demonstration Track) (2009), pp. 1055–1058.details@inproceedings{GA09b, author = {Glavic, Boris and Alonso, Gustavo}, booktitle = {Proceedings of the 35th ACM SIGMOD International Conference on Management of Data (Demonstration Track)}, date-added = {2012-12-14 18:55:49 +0000}, date-modified = {2012-12-14 18:55:49 +0000}, keywords = {Provenance; Perm}, pages = {1055-1058}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09b.pdf}, projects = {Perm}, title = {{The Perm Provenance Management System in Action}}, venueshort = {SIGMOD}, year = {2009}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09b.pdf} }In this demonstration we present the Perm provenance management system (PMS). Perm is capable of computing, storing and querying provenance information for the relational data model. Provenance is computed by using query rewriting techniques to annotate tuples with provenance information. Thus, provenance data and provenance computations are represented as relational data and queries and, hence, can be queried, stored and optimized using standard relational database techniques. This demo shows the complete Perm system and lets attendants examine in detail the process of query rewriting and provenance retrieval in Perm, the most complete data provenance system available today. For example, Perm supports lazy and eager provenance computation, external provenance and various contribution semantics.
-
Provenance for Nested Subqueries
Boris Glavic and Gustavo Alonso
Proceedings of the 12th International Conference on Extending Database Technology (2009), pp. 982–993.details@inproceedings{GA09a, author = {Glavic, Boris and Alonso, Gustavo}, booktitle = {Proceedings of the 12th International Conference on Extending Database Technology}, date-added = {2012-12-14 18:55:49 +0000}, date-modified = {2012-12-14 18:55:49 +0000}, keywords = {Provenance; Perm}, pages = {982-993}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09a.pdf}, projects = {Perm}, slideurl = {http://www.slideshare.net/lordPretzel/edbt-2009-provenance-for-nested-subqueries}, title = {{Provenance for Nested Subqueries}}, venueshort = {EDBT}, year = {2009}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09a.pdf} }Data provenance is essential in applications such as scientific computing, curated databases, and data warehouses. Several systems have been developed that provide provenance functionality for the relational data model. These systems support only a subset of SQL, a severe limitation in practice since most of the application domains that benefit from provenance information use complex queries. Such queries typically involve nested subqueries, aggregation and/or user defined functions. Without support for these constructs, a provenance management system is of limited use. In this paper we address this limitation by exploring the problem of provenance derivation when complex queries are involved. More precisely, we demonstrate that the widely used definition of Why-provenance fails in the presence of nested subqueries, and show how the definition can be modified to produce meaningful results for nested subqueries. We further present query rewrite rules to transform an SQL query into a query propagating provenance. The solution introduced in this paper allows us to track provenance information for a far wider subset of SQL than any of the existing approaches. We have incorporated these ideas into the Perm provenance management system engine and used it to evaluate the feasibility and performance of our approach.
-
Perm: Processing Provenance and Data on the same Data Model through Query Rewriting
Boris Glavic and Gustavo Alonso
Proceedings of the 25th IEEE International Conference on Data Engineering (2009), pp. 174–185.details@inproceedings{GA09, author = {Glavic, Boris and Alonso, Gustavo}, booktitle = {Proceedings of the 25th IEEE International Conference on Data Engineering}, date-added = {2012-12-14 18:55:49 +0000}, date-modified = {2012-12-14 18:55:49 +0000}, keywords = {Provenance; Perm}, pages = {174-185}, pdfurl = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09.pdf}, projects = {Perm}, slideurl = {http://www.slideshare.net/lordPretzel/icde-2009}, title = {{Perm: Processing Provenance and Data on the same Data Model through Query Rewriting}}, venueshort = {ICDE}, year = {2009}, bdsk-url-1 = {http://cs.iit.edu/%7edbgroup/assets/pdfpubls/GA09.pdf} }Data provenance is information that describes how a given data item was produced. The provenance includes source and intermediate data as well as the transformations involved in producing the concrete data item. In the context of a relational databases, the source and intermediate data items are relations, tuples and attribute values. The transformations are SQL queries and/or functions on the relational data items. Existing approaches capture provenance information by extending the underlying data model. This has the intrinsic disadvantage that the provenance must be stored and accessed using a different model than the actual data. In this paper, we present an alternative approach that uses query rewriting to annotate result tuples with provenance information. The rewritten query and its result use the same model and can, thus, be queried, stored and optimized using standard relational database techniques. In the paper we formalize the query rewriting procedures, prove their correctness, and evaluate a first implementation of the ideas using PostgreSQL. As the experiments indicate, our approach efficiently provides provenance information inducing only a small overhead on normal operations.