Empower Data-Intensive Computing:
the integrated data management approach
(NSF CNS-1526887)
Abstract:
From the system point of view, there are two types of data: observational data, the data collected by electrical devices such as sensors, monitors, cameras, etc.; and simulation data, data generated by computing. In general, the latter is used in the traditional scientific high-performance computing (HPC) and requires strong consistency for correctness. The former is popular for newly emerged big data applications and does not require strong consistency. The difference in consistency leads to two kinds of file systems: data-intensive distributed file system, represented by the MapReduce-based Hadoop distributed file systems (HDFS) from Google and Yahoo; and computing-intensive file systems, represented by the high-performance parallel file systems (PFS), such as the IBM general parallel file system (GPFS). These two kinds of file systems are designed with different philosophies, for different applications, and do not talk to each other. They form two separate ecosystems and used by different communities. However, while data-intensive applications become increasingly ubiquitous, understanding huge amounts of collected data starts to require powerful computations; and, in thHigh-Performancenced large-scale computations also demand the ability to handle huge amounts of data, not only because HPC generates more data than before but also advanced data-oriented technologies such as visualization and data mining become a part of general scientific computing. Therefore, HPC and big data requirements are merging. We need an integrated solution for data-intensive HPC and High-Performance data analytics (HPDA). In this research, we propose an Integrated Data Access System (IDAS) to bridge the data management gap.
Personnel:
Principal Investigator:
- Dr. Xian-He Sun, PI, Illinois Institute of Technology (September 2015-present)
- Dr. Shujia Zhou, no-cost, Co-PI, NASA Goddard Space Flight Center (September 2015-present)
Graduate Students:
- Xi Yang, Illinois Institute of Technology/SCS Lab (PhD student, September 2015-August 2017)
- Kun Feng, Illinois Institute of Technology/SCS Lab (PhD student, September 2015-present)
- Anthony Kougkas, Illinois Institute of Technology/SCS Lab (PhD student, September 2016-present)
- Hariharan Devarajan, Illinois Institute of Technology/SCS Lab (PhD student, September 2017-present)
- Nikhita Kataria, Illinois Institute of Technology/SCS Lab (MSc student, January 2017-June 2017)
- Venkata Naga Prajwal Chalia, Illinois Institute of Technology/SCS Lab (MSc student, August 2017-present)
Undergraduate Students:
- Michael Welch, Illinois Institute of Technology/SCS Lab (BSc student, May 2017-September 2017)
- Miles Hood, Illinois Institute of Technology/SCS Lab (BSc student, May 2017-September 2017)
IDAS Framework
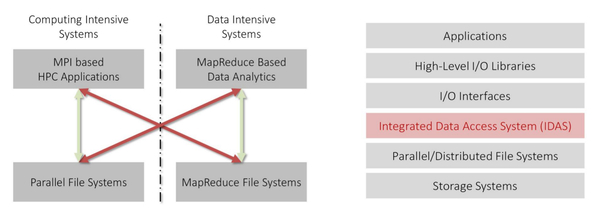
Main Contributions of IDAS:
- Provides a bridge between the data generation and data analysis processes
- Introduces an innovative, truly elastic parallel I/O infrastructure where MapReduce applications can access HPC parallel file systems, and MPI and other HPC systems can access HDFS
- Promotes the integration and collaboration between the model simulation and data analysis communities, and modernizing software infrastructure for big data science and engineering
- Positions general in-situ application-aware dynamic file systems to better handle the big data problem.
The IDAS framework is implemented and tested. In particular, the MapReduce environment to Parallel File Systems (PFSs) direction is fully developed and implemented under NASA environment for NASA applications under the NASA Super Cloud project. The corresponding software system, named PortHadoop, was developed and tested under the NSF Chameleon Cloud computing facility. PortHadoop is reported by HPC wire and the NSF TACC supercomputing center as a successful research project.
IRIS Framework
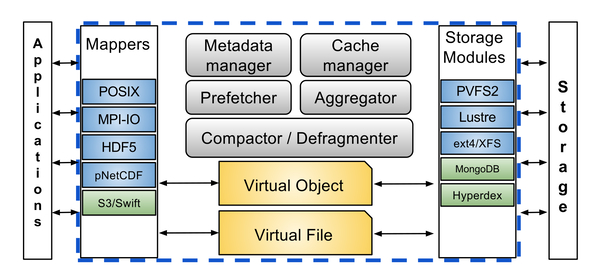
Main Contributions of IRIS:
- Provides a unified storage access system that integrates various underlying storage solutions such as PFSs or Object Stores.
- Introduces two novel abstract ideas, the Virtual File and the Virtual Object that can help map user’s data structures to any data management framework.
- In addition to providing programming convenience and efficiency, IRIS can grant higher performance by up to 7x than existing solutions in the intersection of HPC and HPDA.
Distributed data processing environments have advanced quickly during the last several years. Obviously, supporting only the integration of Hadoop environments with HPC is not good enough now. Currently, we have been working on extending the IDAS idea to support more general integrations and to support the converging of HPC and big data/Cloud environments at the data access level in general. We are developing a new framework, named IRIS, for the extension and continuation.
Publications (some early publications are listed for self-completeness):
- X. Yang, Y. Yin, H. Jin, and X.-H. Sun, "SCALER: Scalable Parallel File Write in HDFS," in Proc. of IEEE International Conference on Cluster Computing 2014 (Cluster'14), Madrid, Spain, Sept. 2014.
- B. Feng, X. Yang, K. Feng, Y. Yin and X.-H. Sun, "IOSIG+: on the Role of I/O Tracing and Analysis for Hadoop Systems," in Proc. of the IEEE International Conference on Cluster Computing 2015 (Cluster'15) (short paper), Chicago, IL, USA, Sept. 2015.
- S. Zhou, X. Yang, X. Li, T. Matsui, S. Liu, X.-H. Sun and W. Tao, "A Hadoop-Based Visualization and Diagnosis Framework for Earth Science Data," in Proc. of Big Data in the Geosciences Workshop, in conjunction with IEEE International Conference on Big Data (IEEE BigData 2015) (short paper). Santa Clara, CA, USA, Oct. 2015.
- X. Yang, N. Liu, B. Feng, X.-H. Sun and S. Zhou, "PortHadoop: Support Direct HPC Data Processing in Hadoop," in Proc. of IEEE International Conference on Big Data (IEEE BigData 2015). Santa Clara, CA, USA, Oct. 2015. (acceptance rate: 17%)
- X. Yang, C. Feng, Z. Xu and X.-H. Sun, "Dominoes: Speculative Repair in Erasure Coded Hadoop System," in Proc. of 22nd annual IEEE International Conference on High Performance Computing (HiPC 2015), Bengaluru, India, Dec. 2015 (acceptance rate: ~24%)
- A. Haider, X. Yang, N. Liu, S. He and X.-H. Sun, "IC-Data: Improving Compressed Data Processing in Hadoop," in Proc. of 22nd annual IEEE International Conference on High Performance Computing (HiPC 2015), Bengaluru, India, Dec. 2015 (acceptance rate: ~24%)
- X. Yang, S. Liu, K. Feng, S. Zhou, and X.-H. Sun, "Visualization and Adaptive Subsetting of Earth Science Data in HDFS - A Novel Data Analysis Strategy with Hadoop and Spark," in Proc. the 6th IEEE International Conference on Big Data and Cloud Computing (BDCloud 2016), Atlanta, GA, Oct. 2016.
- A. Kougkas, H. Eslami, R. Thakur, W. Group and X.-H. Sun, "Rethinking Key Value Store for Parallel I/O Optimization," in International Journal of High Performance Applications, vol. 31, no. 4, pp. 335-356, 2017.
- A. Kougkas, H. Devarajan and X.-H. Sun, "Syndesis: Mapping Objects to Files for a Unified Data Access System," in Proc. of the ACM SIGHPC 8th International Workshop on Many-Task Computing on Clouds, Grids, and Supercomputers (MTAGS 2017), in conjunction with SC'17, Denver, CO, USA, Nov. 2017.
- A. Kougkas, H. Devarajan and X.-H. Sun, "Enosis: Bridging the Semantic Gap between File-based and Object-based Data Models," in Proc. of the ACM SIGHPC 8th International Workshop on Data-Intensive Computing in the Clouds (DataCloud 2017), in conjunction with SC'17, Denver, CO, USA, Nov. 2017.
Software:
PortHadoop library can be found here.
IRIS library will be available soon.
Sponsor:
National Science Foundation
