A High-Performance Storage Infrastructure for Activity and Log Workloads
(NSF CSSI 2104013)
Modern application domains in science and engineering, from astrophysics to web services and financial computations generate massive amounts of data at unprecedented rates (reaching up to 7 TB/s).
The promise of future data utility and the low cost of data storage caused by recent hardware innovations (less than $0.02/GB) is driving this data explosion resulting in widespread data hoarding from researchers and engineers.
This project will design and implement ChronoLog, a distributed and tiered shared log storage ecosystem. ChronoLog uses physical time to distribute log entries while providing total log ordering. It also utilizes multiple storage tiers to elastically scale the log capacity (i.e., auto-tiering). ChronoLog will serve as a foundation for developing scalable new plugins, including a SQL-like query engine for log data, a streaming processor leveraging the time-based data distribution, a log-based key-value store, and a log-based TensorFlow module.
Modern applications spanning from Edge to High Performance
Computing (HPC) systems, produce and process log data and create a
plethora of workload characteristics that rely on a common storage
model:
the distributed shared log

Combining the append-only nature of a log abstraction with the natural strict order of a global truth, such as physical time, can be used to build a distributed shared log store that avoids expensive synchronizations.
An efficient mapping of the log entries to the tiers of the hierarchy (i.e., auto-tiering a log) provides: improved log capacity, tunable access parallelism, and I/O isolation between tail and historical log operations.
ChronoLog offers a powerful, versatile, and scalable primitive that can connect two or more stages of a data processing pipeline (i.e., a producer/consumer model) without explicit control of the data flow while maintaining data durability by providing:
How physical time can be used to distribute and order log data without the need for explicit synchronizations or centralized sequencing offering a high-performance and scalable shared log store with the ability to support efficient range data retrieval.
How multi-tiered storage can be used to scale the capacity of a log and offer tunable data access parallelism while maintaining I/O isolation and a highly concurrent access model supporting multiple-writers-multiple-readers (MWMR).
How elastic storage semantics and dynamic resource provisioning can be used to achieve an efficient matching between I/O production and consumption rates of conflicting workloads under a single system.
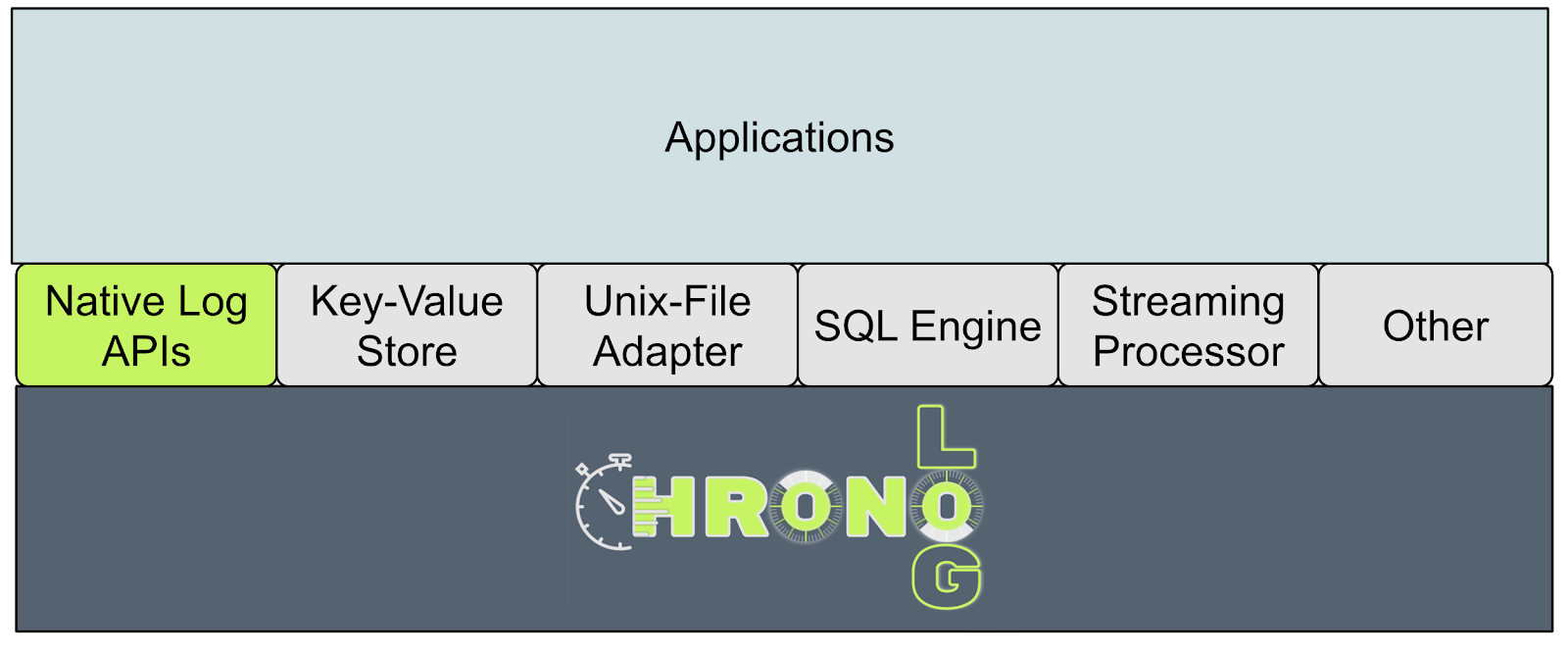
The ChronoLog Core Library
An in-memory lock-free distributed journal with the ability to persist data on flash storage to enable a fast distributed caching layer
A new high-performance data streaming service specifically, but not limited, for HPC systems that uses MPI for job distribution and RPC over RDMA (or over RoCE) for communication
A set of high-level interfaces for I/O
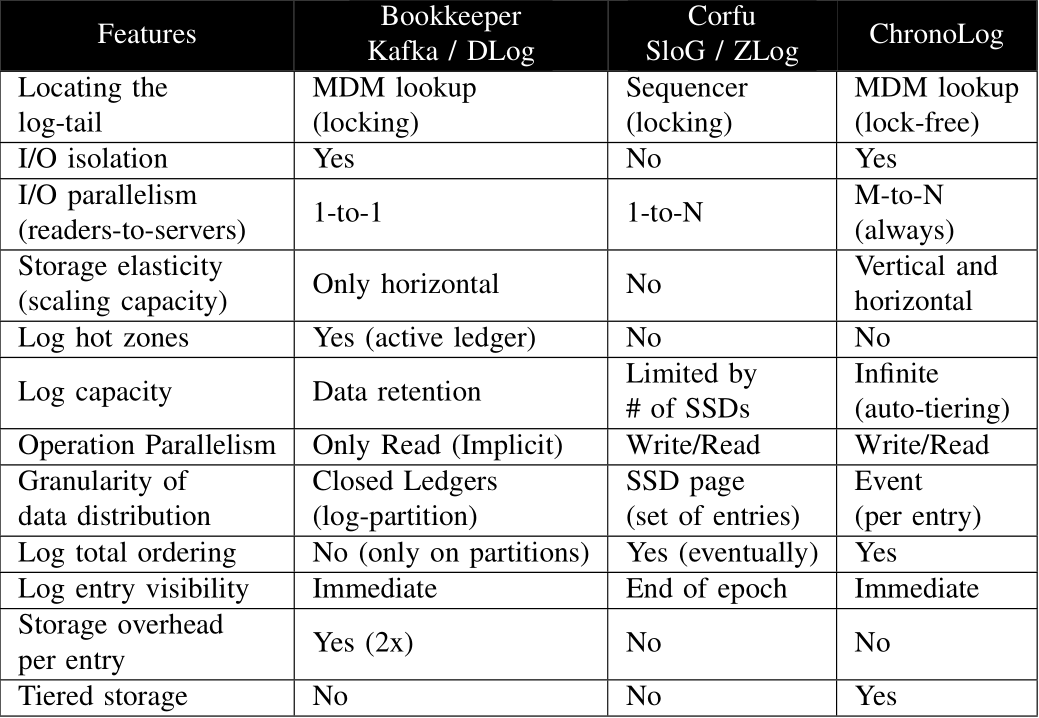
Log data should be distributed at a log-entry (rather than log-partition) granularity, resulting in a highly parallel distribution model. Further, log data should be distributed both horizontally (i.e., multiple nodes) and vertically (i.e., multiple tiers of storage).
Finding the tail of the log should be free of expensive synchronization operations (e.g., metadata locking) or a centralized sequencer that enforces the order. Additionally, the system should guarantee ordering of entries on the entirety of a log and not only on a log-partition granularity.
Interacting with the log should follow a highly concurrent access model providing multiple-writer-multiple-reader (MWMR) semantics. Further, tail and historical log operations should be handled separately via I/O isolation. The log should not favor one type of operation over the other offering high performance for both.
The log must be able to be partially processed via range retrieval mechanisms (i.e., partial get) moving away from the restrictive sequential access model imposed by log iterators.
The log should be able to exploit advantages of different storage tiers. No explicit user intervention should be required. The system should map the natural ordering of log entries to the performance spectrum of each storage tier (e.g., recent entries in faster tiers, older entries in slower) to efficiently expand log capacity.
Log data should be persisted by a tunable parallel I/O model to match the rate of log data production. In other words, the storage infrastructure must be elastic and adaptive via storage auto-scaling leading to better performance and resource utilization.
ChronoLog is a new class of a distributed shared log store that will leverage physical time for achieving total ordering of log entries and will utilize multiple storage tiers to distribute a log both horizontally and vertically (a model we call 3D data distribution).

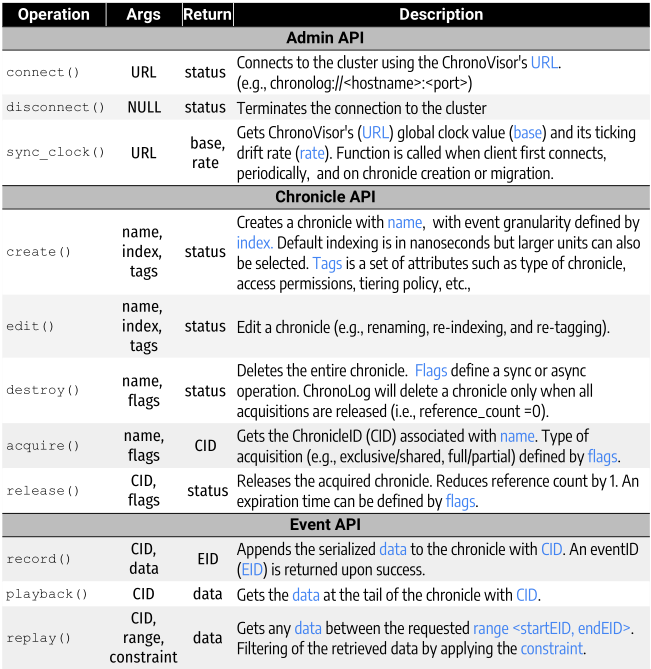


To provide chronicle capacity scaling, ChronoLog moves data down to the next larger but slower tiers automatically. To achieve this, the ChronoGrapher offers a very fast distributed data flushing solution, that can match the event production rate, by offering:

ChronoGrapher runs a data streaming job with three major steps represented as a DAG: event collection, story building, and story writing. Each node in the DAG is dynamic and elastic based on the incoming traffic estimated by the number of events and total size of data.
The ChronoPlayer is responsible for executing historical read operations.

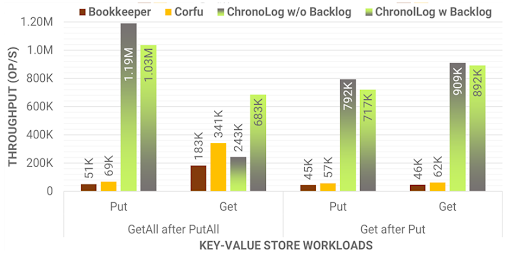
In this test, we evaluate the operation throughput of a key-value store implemented on top of a log. We use the native KVS implementations for comparable log stores: Bookkeeper Table Service, and CorfuDB. For ChronoLog, we implemented a prototype key-value store that simply maps a key to a chronicle event. We run two workloads: a) each client pushes 32K put() calls of 4KB each and then gets all keys sequentially; and b) each client puts and immediately gets keys of 4KB and does so 32K times. For ChronoLog we tested two configurations with and without event caching using a backlog. ChronoLog outperforms both competitive solutions by a significant margin depending on the test case. Specifically, ChronoLog performs 14x faster for put() and 2x-12x for get().
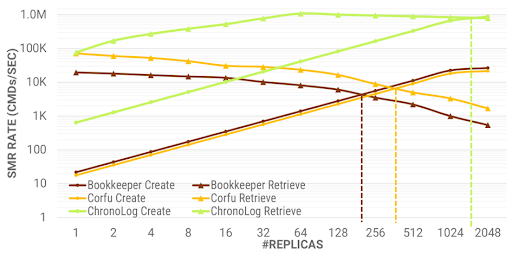
In this test, we investigate the ability of all log stores to effectively provide a fast store for state machine replicas (SMR). In this application, each client appends a command set of 4KB into the log and then it reads all events that contain the command sets from all other processes. The log offers the total ordering required to reach consensus of what command to execute next. As the number of replicas increases, more and more data are pushed to the log and creating and retrieving SMRs will eventually saturate. ChronoLog performs 5x better than Corfu and 10x than Bookkeeper leading to a larger number of replicas being saturated.
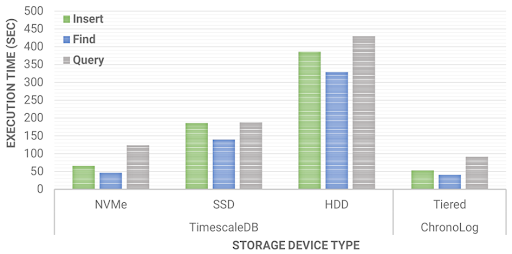
In this test, we compare ChronoLog with TimeScaleDB by running the widely used Time Series Benchmark Suite (TSBS). The application inserts, finds, and queries the data in 4MB data ranges of 4KB events calculating Min, Max, and Average values. Both systems are configured to use the same resources (i.e., number of processes and storage devices). Since ChronoLog is designed to leverage the hierarchical storage environment, it performs up to 25% faster than TimeScaleDB since the chronicle is already indexed by physical time and distributed in multiple tiers.
More results can be found in our most recent paper.

Dr. Xian-He Sun
Principal Investigator
Illinois Tech

Dr. Anthony Kougkas
Co-Principal Investigator
Illinois Tech

Dr. Kyle Chard
Co-Principal Investigator
University of Chicago

Jaime Cernuda Garcia
PhD Student SCS Lab
Illinois Tech

Luke Logan
PhD Student SCS Lab
Illinois Tech

Kun Feng
HPC Engineer
Illinois Tech

Aparna Sasidharan
HPC Engineer
Illinois Tech

Inna Brodkin
Senior HPC Engineer
University of Chicago
Ian Foster
Collaborator
University of Chicago
Stephen Herbein
Collaborator
Lawrence Livermore National Lab
Tom Glanzman
Collaborator
SLAC National Accelerator Lab
Dries Kimpe
Collaborator
3RedPartners
Sam Lang
Collaborator
3RedPartners
Tanu Malik
Collaborator
DePaul University
Benedikt Riedel
Collaborator
University of Wisconsin Madison
Sameer Shende
Collaborator
ParaTools, Inc.
Shaowen Wang
Collaborator
University of Illinois at Urbana-Champaign
Logan Ward
Collaborator
Argonne National Lab
Boyd Wilson
Collaborator
OmniBond Systems LLC
