Lecture Notes for CS425
Lecture
Relations
- $$D_1 = \{ false, true \}$$
- $$D_2 = \{ 1,2,3 \}$$
R = (A,B)
$$D_1 \times D_2$$
| A | B |
|---|---|
| false | 1 |
| false | 2 |
| false | 3 |
| true | 1 |
| true | 2 |
| true | 3 |
| A | B |
|---|---|
| false | 1 |
| true | 1 |
| true | 3 |
| A | B |
|---|---|
| true | 3 |
| false | 1 |
| true | 1 |
PKs and FKs
Instructor
| ID | Name | SSN | salary |
|---|---|---|---|
| 1 | Peter Smith | 11-22 | 4000 |
| 2 | Peter Smith | 22-33 | 5000 |
| 3 | Alice Smith | 55-55 | 4000 |
Superkeysall attributes are always a superkey{ID, Name, SSN, salary }Superkeys:K1 = {ID},K2 = {SSN},K3 = {ID,SSN},K4 = {ID,Name}-
Candidate keysareK1, K2(the only minimal superkeys)- e.g.,
K3 = {ID,SSN}is not minimal, because superkeyK1 = {ID}is a proper subset ofK3
- e.g.,
JSON
-
JSON data allows nesting of object (
{}) and array ([]) collection types- e.g., the value of the address field available for some customers is itself an object
- JSON is semi-structured, e.g., only some customers have an address field
|
|
Lecture
Recap relational model
-
structured data model
- compare to semi-structured (JSON) and unstructure (text document)
Schema vs. Instance (data)
schema
-
relation schema:
R(A1: D1, ..., An: Dn),R(A1, ..., An)Student(Name,CWID,GPA)
-
database schema:
D = {R1, ..., Rm}UniversityDB = { Student(Name,CWID,GPA), Course(Title, Nr, Major), ...
instance (data)
-
relation instance of schema
R(A1: D1, ..., An: Dn):- it is a set of tuples (rows) which is a subset
D1 x ... x Dn
- it is a set of tuples (rows) which is a subset
-
database instance of DB schema
UniversityDB = { Student(Name:string,CWID:string,GPA:float), Course(Title:string, Nr:int, Major:string)}- is a set of relation instance, one for each relation schema
Integrity Constraints
-
candidate keys / primary keys
- super key: set of attributes that uniquely identify each row in a table
- candidate key: minimal superkeys
- primary key: user-selected candidate used to identify rows
-
foreign keys
- "link" tuples from one table to another by referring to the primary key of the other table
foreign key violations
| IName | Dname |
|---|---|
| A | BIO |
| B | BIO |
| C | BIO |
| D | CS |
| E | CS |
| DName | Building |
|---|---|
| BIO | the big building |
| CS | the small building |
- delete BIO
- change departments of existing
BIOinstructors to something else and then delete - (1) change departments of existing
BIOinstructors toNULL - (2) delete instructors for
BIO - (3) don't do it and throw ERROR
- we will see later that relational database implement options (1) to (3) and allow the user to choose when they define a foreign key, which option should be used
Lecture and
Application Domain for Project
banking system
persons (roles)
- clients / account holders
-
employee
- teller
- loan specialist
- manager
data
- account holders
-
accounts
- account types
- loans
processes
-
deposit / withdraw / transfer
- data: accounts
- persons: clients
-
manage accounts (create / close / change type?)
- data: accounts, account holders
- persons: clients, employee
-
loan management
- data: loans, accounts, clients
- persons: employee, clients
-
interest management
- data: accounts
- person: (automatic)
-
analytics
- data: accounts, loans, clients, account types
- person: managers
Postgres Overview
Postgres is a server-based database. That the postgres process runs in the background listing on a network port on the machine you are running it on. You can then connect to the server using a client application that understand the network protocol postgres is using. A Postgres server process manages a directory called the cluster which stores the content of your database on disk. When a postgres server is started, it is assigned a cluster directory to manage. Once you have a running Postgres server you can connect with a client application to send SQL commands to the server and receive results. Some important client applications are discussed below.
Cluster directory
Depending on how you installed Postgres, a cluster directory may have been created for you already. If not then use the initdb command as explained below to create one yourself. A cluster directory is used by Postgres to store your database files. The directory also contains important configuration files:
-
postgresql.conf- configuration settingslisten_addresses = '*'- allow connections from anywhere
-
pg_hba.conf- controls access to the database- each line is rule, first matching rule applies
Postgres binaries
initdb - creates clusters
|
|
pg_ctl - start / stop servers
- start server at cluster directory
DIRwriting logs toLOGFILE
|
|
- stop server at cluster directory
DIR
|
|
psql - commandline client
- connect to running server and run SQL commands
-p- network port-h- host (IP address) where127.0.0.1is localhost-U- postgres user to connect with- last one is the database to connect to (default DB created is
postgres)
|
|
Client applications (pgAdmin)
Many client applications exist that can talk to a postgres server. For our purpose we want a GUI or CLI to iteratively run SQL commands and inspect their results. We already discussed the build-in psql CLI above. And explain how to use pgAdmin a widely used GUI client in the following.
pgAdmin
You can download pgAdmin from here: https://www.pgadmin.org/.
Setup
- When you first start pgAdmin, it will ask you to set a master password. Do that first.
- To add a new database connection for your Postgres server, right-click on the browser shown on the left-hand side and select
Register->Server
- give the server a name (any name would do)
-
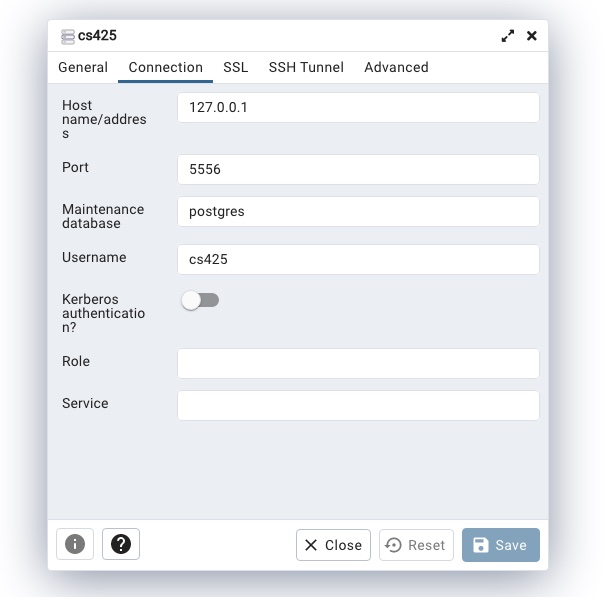
then click on connection and enter the connection information
- host: if you are running postgres locally this would be
127.0.0.1(the local machine) - port: unless you are running the postgres server on a non-standard port this will be
5432 - maintenance database: the first database to connect to (for most installation methods this would be
postgres) - username: your database user name (for most installations this would be
postgres) - password: the password of your database user
- Save password: select yes to not have to enter the password every time you connect to the server
- host: if you are running postgres locally this would be
Inspecting the database schema
To inspect the schema of a database, select the server in the left-hand side browser and expand it. Then expand the schema public and then select tables.
Writing SQL
Rightclick on a database in the browser on the left and select QueryTool
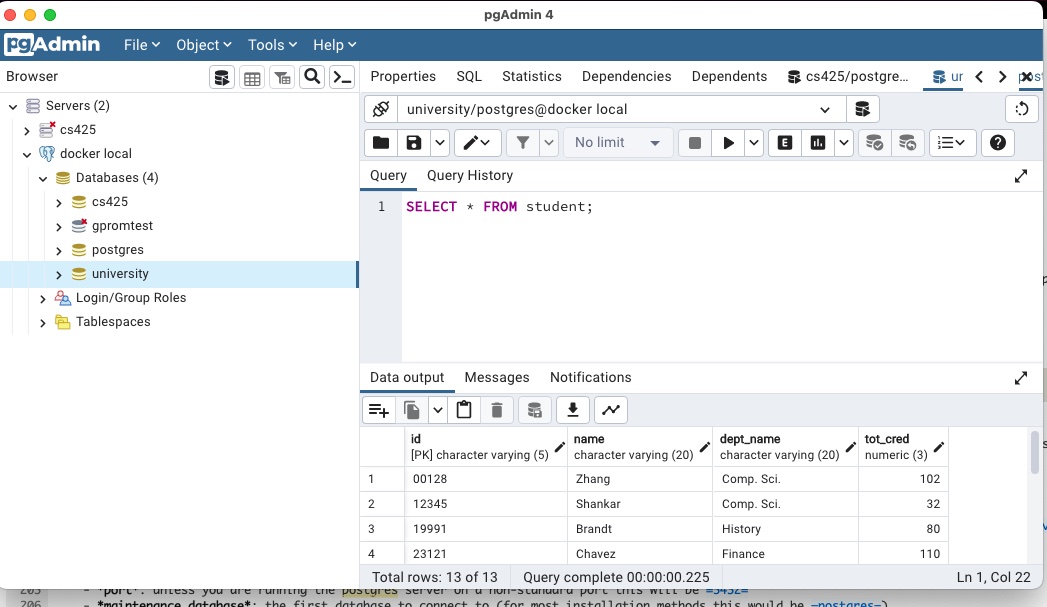
Then you can enter queries and execute them with the "play" button.
Create schema and insert data
The following sql script generates the university example schema. The script is also available here: https://github.com/IITDBGroup/cs425/blob/master/university_schema_postgres.sql
|
|
| DROP TABLE |
|---|
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| DROP TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| CREATE TABLE |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| DELETE 0 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
More DDL examples
- create a table for storing information about seminars
|
|
| CREATE TABLE |
DDL change table definitions
dropping a table
|
|
| DROP TABLE |
alter table
- adding an attribute (new values will be
NULL
|
|
| ALTER TABLE |
|
|
| title | presenter | semdate | building | room_number | organizing_dept |
- add foreign key
|
|
| ALTER TABLE |
DML - inserts and delete
Insert
- insert a single row into a table
|
|
| INSERT 0 1 |
|
|
| INSERT 0 1 |
|
|
| title | presenter | semdate | building | room_number | organizing_dept |
|---|---|---|---|---|---|
| Why databases are great | Bert | 2022-09-28 09:00:00 | Packard | 101 | Comp. Sci. |
| Why databases are stupid | Bert | 2022-09-29 10:00:00 | Packard | 101 | Comp. Sci. |
Delete
- delete all rows that fulfill
WHEREcondition from table
|
|
| DELETE 2 |
|
|
| title | presenter | semdate | building | room_number | organizing_dept |
|
|
| INSERT 0 1 |
|---|
| INSERT 0 1 |
| INSERT 0 1 |
|
|
| title | presenter | semdate | building | room_number | organizing_dept |
|---|---|---|---|---|---|
| Why databases are great | Bert | 2022-09-28 09:00:00 | Packard | 101 | Comp. Sci. |
| Why databases are stupid | Bert | 2022-09-29 10:00:00 | Packard | 101 | Comp. Sci. |
| Why Mozart is great | Alice | 2022-10-30 11:00:00 | Packard | 101 | Music |
|
|
| DELETE 1 |
|
|
| title | presenter | semdate | building | room_number | organizing_dept |
|---|---|---|---|---|---|
| Why databases are great | Bert | 2022-09-28 09:00:00 | Packard | 101 | Comp. Sci. |
| Why databases are stupid | Bert | 2022-09-29 10:00:00 | Packard | 101 | Comp. Sci. |
DML - queries
basic SELECT-FROM-WHERE blocks
examples
*means all attributes from tables in theFROMclause
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 44553 | Peltier | Physics | 56 |
| 45678 | Levy | Physics | 46 |
| 54321 | Williams | Comp. Sci. | 54 |
| 55739 | Sanchez | Music | 38 |
| 70557 | Snow | Physics | 0 |
| 76543 | Brown | Comp. Sci. | 58 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
- Names of students studying CS
|
|
| name |
|---|
| Zhang |
| Shankar |
| Williams |
| Brown |
- alias in
FROMclause:TABLENAME ALIASorTABLENAME AS ALIAS - dot notation to specify which table an attribute belongs to
TABLE.ATTR - in
SELECTclause usASto rename a result columnATTRIBUTE AS NEWNAME
|
|
| name | major | dept_building |
|---|---|---|
| Zhang | Comp. Sci. | Taylor |
| Shankar | Comp. Sci. | Taylor |
| Peltier | Physics | Watson |
| Levy | Physics | Watson |
| Williams | Comp. Sci. | Taylor |
| Snow | Physics | Watson |
| Brown | Comp. Sci. | Taylor |
| Aoi | Elec. Eng. | Taylor |
| Bourikas | Elec. Eng. | Taylor |
| Tanaka | Biology | Watson |
relational algebra equivalence
|
|
is equivalent to $$\pi_{A_1, \ldots, A_n}(\sigma_{P}(R_1 \times \ldots \times R_m)$$
casting
SQL databases automatically cast between datatypes where possible, e.g., in the condition mydatecolumn < '2002-01-01' we are comparing a DATE against a VARCHAR (string) value. Postgres would detect that it does not have a comparison operator < for these types and correctly decide to try to cast '2002-01-01' as a DATE.
You can also manually cast between types:
- cast result of expression as datatype:
expr::datatype - SQL standard
CAST(expr AS datatype)
|
|
| p | x |
|---|---|
| 101 | 101 |
| 514 | 514 |
| 3128 | 3128 |
| 100 | 100 |
| 120 | 120 |
keywords are case-insensitive
|
|
| name |
|---|
| Zhang |
| Shankar |
| Brandt |
| Chavez |
| Peltier |
| Levy |
| Williams |
| Sanchez |
| Snow |
| Brown |
| Aoi |
| Bourikas |
| Tanaka |
joins
natural join
|
|
| id | name | dept_name | salary | course_id | sec_id | semester | year |
|---|---|---|---|---|---|---|---|
| 10101 | Srinivasan | Comp. Sci. | 65000.00 | CS-101 | 1 | Fall | 2009 |
| 10101 | Srinivasan | Comp. Sci. | 65000.00 | CS-315 | 1 | Spring | 2010 |
| 10101 | Srinivasan | Comp. Sci. | 65000.00 | CS-347 | 1 | Fall | 2009 |
| 12121 | Wu | Finance | 90000.00 | FIN-201 | 1 | Spring | 2010 |
| 15151 | Mozart | Music | 40000.00 | MU-199 | 1 | Spring | 2010 |
| 22222 | Einstein | Physics | 95000.00 | PHY-101 | 1 | Fall | 2009 |
| 32343 | El Said | History | 60000.00 | HIS-351 | 1 | Spring | 2010 |
| 45565 | Katz | Comp. Sci. | 75000.00 | CS-101 | 1 | Spring | 2010 |
| 45565 | Katz | Comp. Sci. | 75000.00 | CS-319 | 1 | Spring | 2010 |
| 76766 | Crick | Biology | 72000.00 | BIO-101 | 1 | Summer | 2009 |
| 76766 | Crick | Biology | 72000.00 | BIO-301 | 1 | Summer | 2010 |
| 83821 | Brandt | Comp. Sci. | 92000.00 | CS-190 | 1 | Spring | 2009 |
| 83821 | Brandt | Comp. Sci. | 92000.00 | CS-190 | 2 | Spring | 2009 |
| 83821 | Brandt | Comp. Sci. | 92000.00 | CS-319 | 2 | Spring | 2010 |
| 98345 | Kim | Elec. Eng. | 80000.00 | EE-181 | 1 | Spring | 2009 |
outer joins
LEFT,RIGHT,FULL
|
|
| course_id | title | dept_name | credits | prereq_id |
|---|---|---|---|---|
| BIO-301 | Genetics | Biology | 4 | BIO-101 |
| BIO-399 | Computational Biology | Biology | 3 | BIO-101 |
| CS-190 | Game Design | Comp. Sci. | 4 | CS-101 |
| CS-315 | Robotics | Comp. Sci. | 3 | CS-101 |
| CS-319 | Image Processing | Comp. Sci. | 3 | CS-101 |
| CS-347 | Database System Concepts | Comp. Sci. | 3 | CS-101 |
| EE-181 | Intro. to Digital Systems | Elec. Eng. | 3 | PHY-101 |
| MU-199 | Music Video Production | Music | 3 | |
| HIS-351 | World History | History | 3 | |
| FIN-201 | Investment Banking | Finance | 3 | |
| PHY-101 | Physical Principles | Physics | 4 | |
| BIO-101 | Intro. to Biology | Biology | 4 | |
| CS-101 | Intro. to Computer Science | Comp. Sci. | 4 |
specifying join conditions
NATURALON cond, specify join conditioncond(as in $\theta$-joins)USING (A1, ... An)join on equality on all attributesA1, ..., An
|
|
| name | course_id |
|---|---|
| Srinivasan | CS-101 |
| Srinivasan | CS-315 |
| Srinivasan | CS-347 |
| Wu | FIN-201 |
| Mozart | MU-199 |
| Einstein | PHY-101 |
| El Said | HIS-351 |
| Katz | CS-101 |
| Katz | CS-319 |
| Crick | BIO-101 |
| Crick | BIO-301 |
| Brandt | CS-190 |
| Brandt | CS-190 |
| Brandt | CS-319 |
| Kim | EE-181 |
Lecture
SQL is bag semantics
- bag semantics means we can have duplicates!
|
|
| dept_name |
|---|
| Biology |
| Comp. Sci. |
| Comp. Sci. |
| Comp. Sci. |
| Comp. Sci. |
| Elec. Eng. |
| Elec. Eng. |
| Finance |
| History |
| Music |
| Physics |
| Physics |
| Physics |
subqueries
FROMclause can contain queries (and not just tables)
|
|
| dept_name | building | budget |
|---|---|---|
| Biology | Watson | 90000.00 |
| Comp. Sci. | Taylor | 100000.00 |
| Elec. Eng. | Taylor | 85000.00 |
| Finance | Painter | 120000.00 |
| History | Painter | 50000.00 |
| Music | Packard | 80000.00 |
| Physics | Watson | 70000.00 |
WITH clause
- query
qjcan refer to queryqiifi < j
|
|
|
|
| dept_name | building | budget |
|---|---|---|
| Biology | Watson | 90000.00 |
| Comp. Sci. | Taylor | 100000.00 |
| Elec. Eng. | Taylor | 85000.00 |
| Finance | Painter | 120000.00 |
| History | Painter | 50000.00 |
| Music | Packard | 80000.00 |
| Physics | Watson | 70000.00 |
DISTINCT
- remove duplicates
|
|
| dept_name |
|---|
| Finance |
| History |
| Physics |
| Music |
| Comp. Sci. |
| Biology |
| Elec. Eng. |
String operations
- https://www.postgresql.org/docs/current/functions-string.html
- string contention (
||) and substrings (substring)
|
|
| aid |
|---|
| A00128Z |
| A12345S |
| A19991B |
| A23121C |
| A44553P |
| A45678L |
| A54321W |
| A55739S |
| A70557S |
| A76543B |
| A76653A |
| A98765B |
| A98988T |
-
string pattern matching
LIKE.matches any one character%matches any sequence of characters (including empty sequence)
- return students whose name starts with
Z
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
- return students whose name contains
'a'or starts with'Z'
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 54321 | Williams | Comp. Sci. | 54 |
| 55739 | Sanchez | Music | 38 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
- string length
|
|
| name | namel |
|---|---|
| Zhang | 5 |
| Shankar | 7 |
| Brandt | 6 |
| Chavez | 6 |
| Peltier | 7 |
| Levy | 4 |
| Williams | 8 |
| Sanchez | 7 |
| Snow | 4 |
| Brown | 5 |
| Aoi | 3 |
| Bourikas | 8 |
| Tanaka | 6 |
Case distinction and coalesce
CASE
- list of rules, first condition $c_i$ that matches, we return $e_i$
|
|
|
|
| name | tot_cred | major | is_ready |
|---|---|---|---|
| Zhang | 102 | Comp. Sci. | Ready to graduate |
| Shankar | 32 | Comp. Sci. | Not ready to graduate |
| Brandt | 80 | History | Ready to graduate |
| Chavez | 110 | Finance | Ready to graduate |
| Peltier | 56 | Physics | Ready to graduate |
| Levy | 46 | Physics | Ready to graduate |
| Williams | 54 | Comp. Sci. | Ready to graduate |
| Sanchez | 38 | Music | Not ready to graduate |
| Snow | 0 | Physics | Not ready to graduate |
| Brown | 58 | Comp. Sci. | Ready to graduate |
| Aoi | 60 | Elec. Eng. | Ready to graduate |
| Bourikas | 98 | Elec. Eng. | Ready to graduate |
| Tanaka | 120 | Biology | Ready to graduate |
|
|
| name | tot_cred | major |
|---|---|---|
| Zhang | 102 | Comp. Sci. |
| Brandt | 80 | History |
| Chavez | 110 | Finance |
| Peltier | 56 | Physics |
| Levy | 46 | Physics |
| Williams | 54 | Comp. Sci. |
| Brown | 58 | Comp. Sci. |
| Aoi | 60 | Elec. Eng. |
| Bourikas | 98 | Elec. Eng. |
| Tanaka | 120 | Biology |
|
|
| name | tot_cred | major |
|---|---|---|
| Zhang | 102 | Comp. Sci. |
| Brandt | 80 | History |
| Chavez | 110 | Finance |
| Peltier | 56 | Physics |
| Levy | 46 | Physics |
| Williams | 54 | Comp. Sci. |
| Brown | 58 | Comp. Sci. |
| Aoi | 60 | Elec. Eng. |
| Bourikas | 98 | Elec. Eng. |
| Tanaka | 120 | Biology |
coalesce
- return first non-null value
COALESCE(e1,...,en)return first non-null value
|
|
- insert student with NULL
|
|
| DROP TABLE |
|---|
| CREATE TABLE |
| DELETE 0 |
| INSERT 0 1 |
| INSERT 0 1 |
- can be expressed with
CASE
|
|
| name | tot_cred |
|---|---|
| Peter | 0 |
| Alice | 100 |
IS NULL and IS NOT NULL
- check whether a value is
NULL(or not)
|
|
| name | tot_cred |
|---|---|
| Alice | 100 |
Ordering results
-
ORDER BYclause orders results on a list of expressionsASCascending order (smallest first)DESCdescending order (largest first)
|
|
| name | cid | tot_cred | dept_name |
|---|---|---|---|
| Tanaka | 98988 | 120 | Biology |
| Chavez | 23121 | 110 | Finance |
| Zhang | 00128 | 102 | Comp. Sci. |
| Bourikas | 98765 | 98 | Elec. Eng. |
| Brandt | 19991 | 80 | History |
| Aoi | 76653 | 60 | Elec. Eng. |
| Brown | 76543 | 58 | Comp. Sci. |
| Peltier | 44553 | 56 | Physics |
| Williams | 54321 | 54 | Comp. Sci. |
| Levy | 45678 | 46 | Physics |
| Sanchez | 55739 | 38 | Music |
| Shankar | 12345 | 32 | Comp. Sci. |
| Snow | 70557 | 0 | Physics |
Set operations
-
three set operations
UNION,INTERSECT, andEXCEPT(set difference)-
come in two flavors:
setversionbagversion (by addALLafter the operation)
- applied to queries
|
|
set union
|
|
| name |
|---|
| Aoi |
| Bourikas |
| Brandt |
| Brown |
| Califieri |
| Chavez |
| Crick |
| Einstein |
| El Said |
| Gold |
| Katz |
| Kim |
| Levy |
| Mozart |
| Peltier |
| Sanchez |
| Shankar |
| Singh |
| Snow |
| Srinivasan |
| Tanaka |
| Williams |
| Wu |
| Zhang |
bag union
- if we have
nduplicate of a row in the left input andmduplicates in the right input, then there willn + mduplicates of this row in the result ofUNION ALL
|
|
| name |
|---|
| Aoi |
| Bourikas |
| Brandt |
| Brandt |
| Brown |
| Califieri |
| Chavez |
| Crick |
| Einstein |
| El Said |
| Gold |
| Katz |
| Kim |
| Levy |
| Mozart |
| Peltier |
| Sanchez |
| Shankar |
| Singh |
| Snow |
| Srinivasan |
| Tanaka |
| Williams |
| Wu |
| Zhang |
|
|
| name |
|---|
| Aoi |
| Bourikas |
| Brandt |
| Brandt |
| Brandt |
| Brown |
| Califieri |
| Califieri |
| Chavez |
| Crick |
| Crick |
| Einstein |
| Einstein |
| El Said |
| El Said |
| Gold |
| Gold |
| Katz |
| Katz |
| Kim |
| Kim |
| Levy |
| Mozart |
| Mozart |
| Peltier |
| Sanchez |
| Shankar |
| Singh |
| Singh |
| Snow |
| Srinivasan |
| Srinivasan |
| Tanaka |
| Williams |
| Wu |
| Wu |
| Zhang |
set & bag intersection
- set intersection
|
|
| name |
|---|
| Brandt |
-
bag intersection
- if we have
nduplicate of a row in the left input andmduplicates in the right input, then there willmin(n,m)duplicates of this row in the result ofUNION ALL
- if we have
|
|
| name |
|---|
| Brandt |
| Brandt |
set & bag difference
|
|
| name |
|---|
| Aoi |
| Bourikas |
| Brown |
| Chavez |
| Levy |
| Peltier |
| Sanchez |
| Shankar |
| Snow |
| Tanaka |
| Williams |
| Zhang |
- no
Brandt -
bag intersection
- if we have
nduplicate of a row in the left input andmduplicates in the right input, then there willmax(n - m, 0)duplicates of this row in the result ofEXCEPT ALL
- if we have
|
|
| name |
|---|
| Aoi |
| Aoi |
| Aoi |
| Bourikas |
| Bourikas |
| Bourikas |
| Brandt |
| Brandt |
| Brown |
| Brown |
| Brown |
| Chavez |
| Chavez |
| Chavez |
| Levy |
| Levy |
| Levy |
| Peltier |
| Peltier |
| Peltier |
| Sanchez |
| Sanchez |
| Sanchez |
| Shankar |
| Shankar |
| Shankar |
| Snow |
| Snow |
| Snow |
| Tanaka |
| Tanaka |
| Tanaka |
| Williams |
| Williams |
| Williams |
| Zhang |
| Zhang |
| Zhang |
Aggregation and Grouping
-
aggregation are part of the
SELECTclausecount,avg,min,max,sum
|
|
| num_students | avgcred |
|---|---|
| 13 | 65.6923076923076923 |
GROUP BYclause
|
|
| major | num_students | avgcred |
|---|---|---|
| Finance | 0.001 | 36.67 |
| History | 0.001 | 26.67 |
| Physics | 0.003 | 11.33 |
| Music | 0.001 | 12.67 |
| Comp. Sci. | 0.004 | 20.50 |
| Biology | 0.001 | 40.00 |
| Elec. Eng. | 0.002 | 26.33 |
- if aggregation and / or group by used, only group-by expressions or aggregated columns can be used in the
SELECTclause
|
|
ERROR: column "student.name" must appear in the GROUP BY clause or be used in an aggregate function LINE 1: SELECT name, dept_name AS major, count(*)::float / 1000.0 AS...
Lecture
Aggregation and NULL and empty inputs
empty tables
|
|
| CREATE TABLE |
countover an empty table returns 0sumand other aggregates returnNULL
|
|
| count | sum | ?column? |
|---|---|---|
| 0 | t |
some null values in tables
|
|
| INSERT 0 1 |
|---|
| INSERT 0 1 |
|
|
| a | b |
|---|---|
| 10 | |
| 20 |
|
|
| count | sum | ?column? |
|---|---|---|
| 2 | t |
|
|
| INSERT 0 1 |
|---|
| INSERT 0 1 |
- if there are some non-null values, all null values are ignored
|
|
| count | sum | ?column? |
|---|---|---|
| 4 | 10 | f |
Aggregation with HAVING
- filter departments with less than 3 students
|
|
| nst | dept_name |
|---|---|
| 1 | Finance |
| 1 | History |
| 1 | Music |
| 1 | Biology |
| 2 | Elec. Eng. |
-
HAVINGclause filters after aggregation, evaluated afterGROUP BY, but beforeSELECT- can only refer to group-by expression and aggregated results
|
|
| nst | dept_name |
|---|---|
| 1 | Finance |
| 1 | History |
| 1 | Music |
| 1 | Biology |
| 2 | Elec. Eng. |
LIMIT and OFFSET and top-k queries
- order students on
tot_creds
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 98988 | Tanaka | Biology | 120 |
| 23121 | Chavez | Finance | 110 |
| 00128 | Zhang | Comp. Sci. | 102 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 19991 | Brandt | History | 80 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 76543 | Brown | Comp. Sci. | 58 |
| 44553 | Peltier | Physics | 56 |
| 54321 | Williams | Comp. Sci. | 54 |
| 45678 | Levy | Physics | 46 |
| 55739 | Sanchez | Music | 38 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 70557 | Snow | Physics | 0 |
-
LIMIT nreturns the firstnrow- evaluated after
ORDER BY
- evaluated after
- return 3 students with highest
tot_cred
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 98988 | Tanaka | Biology | 120 |
| 23121 | Chavez | Finance | 110 |
| 00128 | Zhang | Comp. Sci. | 102 |
- return 3 students with lowest
tot_cred
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 70557 | Snow | Physics | 0 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 55739 | Sanchez | Music | 38 |
-
OFFSET nskips firstnrows- return 4th to 6th students with highest
tot_cred
- return 4th to 6th students with highest
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 98765 | Bourikas | Elec. Eng. | 98 |
| 19991 | Brandt | History | 80 |
| 76653 | Aoi | Elec. Eng. | 60 |
Bag (multiset) relational algebra
Nested & correlated subqueries
scalar subqueries
- students whose
tot_credare larger than the avgtot_cred
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
- scalar subqueries are queries that evaluate to a single row, and can be used like scalar values in, e.g.,
WHEREclause
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
-
what happens if scalar subquery returns more than one row?
- runtime error
|
|
EXISTS subqueries
EXISTS qis a boolean operator that returns true, ifqreturns at least result,falseotherwise
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 44553 | Peltier | Physics | 56 |
| 45678 | Levy | Physics | 46 |
| 54321 | Williams | Comp. Sci. | 54 |
| 55739 | Sanchez | Music | 38 |
| 70557 | Snow | Physics | 0 |
| 76543 | Brown | Comp. Sci. | 58 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
IN subqueries
- return CS instructors that teach at least one course
|
|
| id | name | dept_name | salary |
|---|---|---|---|
| 10101 | Srinivasan | Comp. Sci. | 65000.00 |
| 12121 | Wu | Finance | 90000.00 |
| 15151 | Mozart | Music | 40000.00 |
| 22222 | Einstein | Physics | 95000.00 |
| 32343 | El Said | History | 60000.00 |
| 45565 | Katz | Comp. Sci. | 75000.00 |
| 76766 | Crick | Biology | 72000.00 |
| 83821 | Brandt | Comp. Sci. | 92000.00 |
| 98345 | Kim | Elec. Eng. | 80000.00 |
correlations
-
use attribute from the outer query inside the nested subquery (inner query)
- semantics: for each row from the outer query
FROMclause substitute its values for the correlated attributes, then evaluate the resulting inner query.
- semantics: for each row from the outer query
- find students where there is at least one student in the same department that has
tot_cred > 100
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 23121 | Chavez | Finance | 110 |
| 54321 | Williams | Comp. Sci. | 54 |
| 76543 | Brown | Comp. Sci. | 58 |
| 98988 | Tanaka | Biology | 120 |
Lecture
nested subqueries
example of evaluating nested subqueries with correlations
- find students where there is at least one student in the same department that has
tot_cred > 100
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 23121 | Chavez | Finance | 110 |
| 54321 | Williams | Comp. Sci. | 54 |
| 76543 | Brown | Comp. Sci. | 58 |
| 98988 | Tanaka | Biology | 120 |
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 98988 | Tanaka | Biology | 120 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 54321 | Williams | Comp. Sci. | 54 |
| 00128 | Zhang | Comp. Sci. | 102 |
| 76543 | Brown | Comp. Sci. | 58 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 23121 | Chavez | Finance | 110 |
| 19991 | Brandt | History | 80 |
| 55739 | Sanchez | Music | 38 |
| 44553 | Peltier | Physics | 56 |
| 70557 | Snow | Physics | 0 |
| 45678 | Levy | Physics | 46 |
- foreach student, replacet
s1.dept_namewith the student'sdept_nameand then evaluate the query andWHERE
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 12345 | Shankar | Comp. Sci. | 32 |
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
|
|
| exists |
|---|
| t |
other nesting constructs ANY and ALL
-
ANYandALLcan be used comparison operatorsANYreturns true if for at least one result of the nested query the comparison evaluates to trueALLreturns true if for all results of the nested query the comparison evaluates to true
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 98988 | Tanaka | Biology | 120 |
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 00128 | Zhang | Comp. Sci. | 102 |
| 12345 | Shankar | Comp. Sci. | 32 |
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 44553 | Peltier | Physics | 56 |
| 45678 | Levy | Physics | 46 |
| 54321 | Williams | Comp. Sci. | 54 |
| 55739 | Sanchez | Music | 38 |
| 76543 | Brown | Comp. Sci. | 58 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
|
|
| id | name | dept_name | tot_cred |
universal quantification with nested subqueries
EXISTSis a boolean operator, so we can for example, negate it- students that are the only students in their department
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 55739 | Sanchez | Music | 38 |
| 98988 | Tanaka | Biology | 120 |
-
departments where all of the students have a
tot_cred > 70- first with
ALL
- first with
|
|
| dept_name |
|---|
| Biology |
| Finance |
| History |
|
|
| dept_name |
|---|
| Finance |
| History |
| Biology |
-
Give me the name of students that have taken all Biology classes
-
for student s, FORALL x in Biology classes: EXISTS takes(s,x)
- NOT EXISTS x in Biology classes: (NOT EXISTS takes(s,x))
-
|
|
| id |
Window functions
OVER()
|
|
| name | avgc |
|---|---|
| Zhang | 65.6923076923076923 |
| Shankar | 65.6923076923076923 |
| Brandt | 65.6923076923076923 |
| Chavez | 65.6923076923076923 |
| Peltier | 65.6923076923076923 |
| Levy | 65.6923076923076923 |
| Williams | 65.6923076923076923 |
| Sanchez | 65.6923076923076923 |
| Snow | 65.6923076923076923 |
| Brown | 65.6923076923076923 |
| Aoi | 65.6923076923076923 |
| Bourikas | 65.6923076923076923 |
| Tanaka | 65.6923076923076923 |
PARTITION BY- basically group by
|
|
| name | tot_cred | dept_name | tcred |
|---|---|---|---|
| Tanaka | 120 | Biology | 120.0000000000000000 |
| Shankar | 32 | Comp. Sci. | 61.5000000000000000 |
| Williams | 54 | Comp. Sci. | 61.5000000000000000 |
| Zhang | 102 | Comp. Sci. | 61.5000000000000000 |
| Brown | 58 | Comp. Sci. | 61.5000000000000000 |
| Aoi | 60 | Elec. Eng. | 79.0000000000000000 |
| Bourikas | 98 | Elec. Eng. | 79.0000000000000000 |
| Chavez | 110 | Finance | 110.0000000000000000 |
| Brandt | 80 | History | 80.0000000000000000 |
| Sanchez | 38 | Music | 38.0000000000000000 |
| Peltier | 56 | Physics | 34.0000000000000000 |
| Snow | 0 | Physics | 34.0000000000000000 |
| Levy | 46 | Physics | 34.0000000000000000 |
- can also include / exclude rows based on ordering
|
|
| name | tot_cred | dept_name | tcred |
|---|---|---|---|
| Snow | 0 | Physics | 0 |
| Shankar | 32 | Comp. Sci. | 32 |
| Sanchez | 38 | Music | 70 |
| Levy | 46 | Physics | 116 |
| Williams | 54 | Comp. Sci. | 170 |
| Peltier | 56 | Physics | 226 |
| Brown | 58 | Comp. Sci. | 284 |
| Aoi | 60 | Elec. Eng. | 344 |
| Brandt | 80 | History | 424 |
| Bourikas | 98 | Elec. Eng. | 522 |
| Zhang | 102 | Comp. Sci. | 624 |
| Chavez | 110 | Finance | 734 |
| Tanaka | 120 | Biology | 854 |
|
|
| name | tot_cred | dept_name | tcred |
|---|---|---|---|
| Snow | 0 | Physics | 854 |
| Shankar | 32 | Comp. Sci. | 854 |
| Sanchez | 38 | Music | 822 |
| Levy | 46 | Physics | 784 |
| Williams | 54 | Comp. Sci. | 738 |
| Peltier | 56 | Physics | 684 |
| Brown | 58 | Comp. Sci. | 628 |
| Aoi | 60 | Elec. Eng. | 570 |
| Brandt | 80 | History | 510 |
| Bourikas | 98 | Elec. Eng. | 430 |
| Zhang | 102 | Comp. Sci. | 332 |
| Chavez | 110 | Finance | 230 |
| Tanaka | 120 | Biology | 120 |
|
|
| name | tot_cred | dept_name | tcred |
|---|---|---|---|
| Snow | 0 | Physics | 32 |
| Shankar | 32 | Comp. Sci. | 70 |
| Sanchez | 38 | Music | 116 |
| Levy | 46 | Physics | 138 |
| Williams | 54 | Comp. Sci. | 156 |
| Peltier | 56 | Physics | 168 |
| Brown | 58 | Comp. Sci. | 174 |
| Aoi | 60 | Elec. Eng. | 198 |
| Brandt | 80 | History | 238 |
| Bourikas | 98 | Elec. Eng. | 280 |
| Zhang | 102 | Comp. Sci. | 310 |
| Chavez | 110 | Finance | 332 |
| Tanaka | 120 | Biology | 230 |
-
specify how many rows to include
-
ROWS BETWEEN x AND yn PRECEDINGn FOLLOWINGUNLIMITED PRECEDING / FOLLOWINGCURRENT ROW
-
|
|
| name | tot_cred | dept_name | tcred |
|---|---|---|---|
| Snow | 0 | Physics | |
| Shankar | 32 | Comp. Sci. | |
| Sanchez | 38 | Music | 0 |
| Levy | 46 | Physics | 0 |
| Williams | 54 | Comp. Sci. | 32 |
| Peltier | 56 | Physics | 38 |
| Brown | 58 | Comp. Sci. | 46 |
| Aoi | 60 | Elec. Eng. | 54 |
| Brandt | 80 | History | 56 |
| Bourikas | 98 | Elec. Eng. | 58 |
| Zhang | 102 | Comp. Sci. | 60 |
| Chavez | 110 | Finance | 80 |
| Tanaka | 120 | Biology | 98 |
Lecture
window functions
|
|
| CREATE TABLE |
|---|
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
|
|
| year | month | totsales |
|---|---|---|
| 2022 | 1 | 40.54 |
| 2022 | 2 | 100.54 |
| 2022 | 3 | 12.20 |
| 2022 | 4 | 66.66 |
| 2022 | 5 | 8.89 |
| 2022 | 6 | 10.00 |
| 2022 | 7 | 100.00 |
| 2022 | 8 | 54453.12 |
| 2022 | 9 | 12.10 |
| 2022 | 10 | 15.34 |
| 2022 | 11 | 65.33 |
| 2022 | 12 | 102.20 |
- running total of sales in 2022 over the month
|
|
| year | month | totsales | running_total |
|---|---|---|---|
| 2022 | 1 | 40.54 | 40.54 |
| 2022 | 2 | 100.54 | 141.08 |
| 2022 | 3 | 12.20 | 153.28 |
| 2022 | 4 | 66.66 | 219.94 |
| 2022 | 5 | 8.89 | 228.83 |
| 2022 | 6 | 10.00 | 238.83 |
| 2022 | 7 | 100.00 | 338.83 |
| 2022 | 8 | 54453.12 | 54791.95 |
| 2022 | 9 | 12.10 | 54804.05 |
| 2022 | 10 | 15.34 | 54819.39 |
| 2022 | 11 | 65.33 | 54884.72 |
| 2022 | 12 | 102.20 | 54986.92 |
- sales for current month and the two previous months
|
|
| year | month | totsales | running_3_month_total |
|---|---|---|---|
| 2022 | 1 | 40.54 | 40.54 |
| 2022 | 2 | 100.54 | 141.08 |
| 2022 | 3 | 12.20 | 153.28 |
| 2022 | 4 | 66.66 | 179.40 |
| 2022 | 5 | 8.89 | 87.75 |
| 2022 | 6 | 10.00 | 85.55 |
| 2022 | 7 | 100.00 | 118.89 |
| 2022 | 8 | 54453.12 | 54563.12 |
| 2022 | 9 | 12.10 | 54565.22 |
| 2022 | 10 | 15.34 | 54480.56 |
| 2022 | 11 | 65.33 | 92.77 |
| 2022 | 12 | 102.20 | 182.87 |
recursive queries (views)
- flights
(Boston, Chicago, 'United', 544)
|
|
| DROP TABLE |
|---|
| CREATE TABLE |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
|
|
| origin | destination | airline | flightnr |
|---|---|---|---|
| ORD | SEA | UA | 455 |
| SEA | LAX | UA | 560 |
| SEA | ORD | UA | 566 |
| SEA | BER | DE | 111 |
| BER | PAR | LH | 666 |
- is there a direct connection from
ORDtoBER
|
|
| origin | destination | airline | flightnr |
- is there a direct connection from
ORDtoBERwith at most one stop
|
|
| numstops |
|---|
| 1 |
| 3 |
-
way to express recursive computations in SQL
-
fixpoint computation:
- initialization (specifies initial content)
- recursive step (compute next iteration content based on current content)
-
|
|
| origin | destination | numstops |
|---|---|---|
| ORD | BER | 1 |
| ORD | BER | 3 |
| ORD | BER | 5 |
| ORD | BER | 7 |
| ORD | BER | 9 |
| ORD | LAX | 1 |
| ORD | LAX | 3 |
| ORD | LAX | 5 |
| ORD | LAX | 7 |
| ORD | LAX | 9 |
| ORD | ORD | 1 |
| ORD | ORD | 3 |
| ORD | ORD | 5 |
| ORD | ORD | 7 |
| ORD | ORD | 9 |
| ORD | PAR | 2 |
| ORD | PAR | 4 |
| ORD | PAR | 6 |
| ORD | PAR | 8 |
| ORD | PAR | 10 |
| ORD | SEA | 0 |
| ORD | SEA | 2 |
| ORD | SEA | 4 |
| ORD | SEA | 6 |
| ORD | SEA | 8 |
| ORD | SEA | 10 |
- this is a fixpoint computation
- initialization, let $T_i$ is the state of the result at iteration $i$
\[ T_0 = Q_{init}(D) \]
- recusive steps
\[ T_{i+1} = T_i \cup Q_{recursive}(T_i, D) \]
- termination: $T_{i+1} = T_{i}$
explaining query plans
Lecture
DDL
views
- how many students per department
|
|
| DROP VIEW |
|---|
| CREATE VIEW |
|
|
| dept_name | headcnt |
|---|---|
| History | 1 |
| Music | 1 |
| Biology | 1 |
| Elec. Eng. | 2 |
| Finance | 1 |
- this is equivalent to
|
|
| dept_name | headcnt |
|---|---|
| History | 1 |
| Music | 1 |
| Biology | 1 |
| Elec. Eng. | 2 |
| Finance | 1 |
- materialized view store the view result
|
|
| DROP VIEW |
|---|
| SELECT 7 |
|
|
| dept_name | headcnt |
|---|---|
| History | 1 |
| Music | 1 |
| Biology | 1 |
| Elec. Eng. | 2 |
| Finance | 1 |
- when the base tables are updated, materialized views get "out of sync"
- use
REFRESHto make sure the view is up to date.
|
|
|
|
|
|
|
|
| dept_name | headcnt |
|---|---|
| History | 1 |
| Music | 1 |
| Physics | 3 |
| Biology | 1 |
| Elec. Eng. | 2 |
| Finance | 1 |
| Comp. Sci. | 2 |
catalog (information schema)
- catalog makes schema information query-able
|
|
| table_schema | table_name | table_type |
|---|---|---|
| information_schema | _pg_foreign_data_wrappers | VIEW |
| information_schema | _pg_foreign_servers | VIEW |
| information_schema | _pg_foreign_table_columns | VIEW |
| information_schema | _pg_foreign_tables | VIEW |
| information_schema | _pg_user_mappings | VIEW |
| information_schema | administrable_role_authorizations | VIEW |
| information_schema | applicable_roles | VIEW |
| information_schema | attributes | VIEW |
| information_schema | character_sets | VIEW |
| information_schema | check_constraint_routine_usage | VIEW |
| information_schema | check_constraints | VIEW |
| information_schema | collation_character_set_applicability | VIEW |
| information_schema | collations | VIEW |
| information_schema | column_column_usage | VIEW |
| information_schema | column_domain_usage | VIEW |
| information_schema | column_options | VIEW |
| information_schema | column_privileges | VIEW |
| information_schema | column_udt_usage | VIEW |
| information_schema | columns | VIEW |
| information_schema | constraint_column_usage | VIEW |
| information_schema | constraint_table_usage | VIEW |
| information_schema | data_type_privileges | VIEW |
| information_schema | domain_constraints | VIEW |
| information_schema | domain_udt_usage | VIEW |
| information_schema | domains | VIEW |
| information_schema | element_types | VIEW |
| information_schema | enabled_roles | VIEW |
| information_schema | foreign_data_wrapper_options | VIEW |
| information_schema | foreign_data_wrappers | VIEW |
| information_schema | foreign_server_options | VIEW |
| information_schema | foreign_servers | VIEW |
| information_schema | foreign_table_options | VIEW |
| information_schema | foreign_tables | VIEW |
| information_schema | information_schema_catalog_name | VIEW |
| information_schema | key_column_usage | VIEW |
| information_schema | parameters | VIEW |
| information_schema | referential_constraints | VIEW |
| information_schema | role_column_grants | VIEW |
| information_schema | role_routine_grants | VIEW |
| information_schema | role_table_grants | VIEW |
| information_schema | role_udt_grants | VIEW |
| information_schema | role_usage_grants | VIEW |
| information_schema | routine_column_usage | VIEW |
| information_schema | routine_privileges | VIEW |
| information_schema | routine_routine_usage | VIEW |
| information_schema | routine_sequence_usage | VIEW |
| information_schema | routine_table_usage | VIEW |
| information_schema | routines | VIEW |
| information_schema | schemata | VIEW |
| information_schema | sequences | VIEW |
| information_schema | sql_features | BASE TABLE |
| information_schema | sql_implementation_info | BASE TABLE |
| information_schema | sql_parts | BASE TABLE |
| information_schema | sql_sizing | BASE TABLE |
| information_schema | table_constraints | VIEW |
| information_schema | table_privileges | VIEW |
| information_schema | tables | VIEW |
| information_schema | transforms | VIEW |
| information_schema | triggered_update_columns | VIEW |
| information_schema | triggers | VIEW |
| information_schema | udt_privileges | VIEW |
| information_schema | usage_privileges | VIEW |
| information_schema | user_defined_types | VIEW |
| information_schema | user_mapping_options | VIEW |
| information_schema | user_mappings | VIEW |
| information_schema | view_column_usage | VIEW |
| information_schema | view_routine_usage | VIEW |
| information_schema | view_table_usage | VIEW |
| information_schema | views | VIEW |
| pg_catalog | pg_aggregate | BASE TABLE |
| pg_catalog | pg_am | BASE TABLE |
| pg_catalog | pg_amop | BASE TABLE |
| pg_catalog | pg_amproc | BASE TABLE |
| pg_catalog | pg_attrdef | BASE TABLE |
| pg_catalog | pg_attribute | BASE TABLE |
| pg_catalog | pg_auth_members | BASE TABLE |
| pg_catalog | pg_authid | BASE TABLE |
| pg_catalog | pg_available_extension_versions | VIEW |
| pg_catalog | pg_available_extensions | VIEW |
| pg_catalog | pg_backend_memory_contexts | VIEW |
| pg_catalog | pg_cast | BASE TABLE |
| pg_catalog | pg_class | BASE TABLE |
| pg_catalog | pg_collation | BASE TABLE |
| pg_catalog | pg_config | VIEW |
| pg_catalog | pg_constraint | BASE TABLE |
| pg_catalog | pg_conversion | BASE TABLE |
| pg_catalog | pg_cursors | VIEW |
| pg_catalog | pg_database | BASE TABLE |
| pg_catalog | pg_db_role_setting | BASE TABLE |
| pg_catalog | pg_default_acl | BASE TABLE |
| pg_catalog | pg_depend | BASE TABLE |
| pg_catalog | pg_description | BASE TABLE |
| pg_catalog | pg_enum | BASE TABLE |
| pg_catalog | pg_event_trigger | BASE TABLE |
| pg_catalog | pg_extension | BASE TABLE |
| pg_catalog | pg_file_settings | VIEW |
| pg_catalog | pg_foreign_data_wrapper | BASE TABLE |
| pg_catalog | pg_foreign_server | BASE TABLE |
| pg_catalog | pg_foreign_table | BASE TABLE |
| pg_catalog | pg_group | VIEW |
| pg_catalog | pg_hba_file_rules | VIEW |
| pg_catalog | pg_index | BASE TABLE |
| pg_catalog | pg_indexes | VIEW |
| pg_catalog | pg_inherits | BASE TABLE |
| pg_catalog | pg_init_privs | BASE TABLE |
| pg_catalog | pg_language | BASE TABLE |
| pg_catalog | pg_largeobject | BASE TABLE |
| pg_catalog | pg_largeobject_metadata | BASE TABLE |
| pg_catalog | pg_locks | VIEW |
| pg_catalog | pg_matviews | VIEW |
| pg_catalog | pg_namespace | BASE TABLE |
| pg_catalog | pg_opclass | BASE TABLE |
| pg_catalog | pg_operator | BASE TABLE |
| pg_catalog | pg_opfamily | BASE TABLE |
| pg_catalog | pg_partitioned_table | BASE TABLE |
| pg_catalog | pg_policies | VIEW |
| pg_catalog | pg_policy | BASE TABLE |
| pg_catalog | pg_prepared_statements | VIEW |
| pg_catalog | pg_prepared_xacts | VIEW |
| pg_catalog | pg_proc | BASE TABLE |
| pg_catalog | pg_publication | BASE TABLE |
| pg_catalog | pg_publication_rel | BASE TABLE |
| pg_catalog | pg_publication_tables | VIEW |
| pg_catalog | pg_range | BASE TABLE |
| pg_catalog | pg_replication_origin | BASE TABLE |
| pg_catalog | pg_replication_origin_status | VIEW |
| pg_catalog | pg_replication_slots | VIEW |
| pg_catalog | pg_rewrite | BASE TABLE |
| pg_catalog | pg_roles | VIEW |
| pg_catalog | pg_rules | VIEW |
| pg_catalog | pg_seclabel | BASE TABLE |
| pg_catalog | pg_seclabels | VIEW |
| pg_catalog | pg_sequence | BASE TABLE |
| pg_catalog | pg_sequences | VIEW |
| pg_catalog | pg_settings | VIEW |
| pg_catalog | pg_shadow | VIEW |
| pg_catalog | pg_shdepend | BASE TABLE |
| pg_catalog | pg_shdescription | BASE TABLE |
| pg_catalog | pg_shmem_allocations | VIEW |
| pg_catalog | pg_shseclabel | BASE TABLE |
| pg_catalog | pg_stat_activity | VIEW |
| pg_catalog | pg_stat_all_indexes | VIEW |
| pg_catalog | pg_stat_all_tables | VIEW |
| pg_catalog | pg_stat_archiver | VIEW |
| pg_catalog | pg_stat_bgwriter | VIEW |
| pg_catalog | pg_stat_database | VIEW |
| pg_catalog | pg_stat_database_conflicts | VIEW |
| pg_catalog | pg_stat_gssapi | VIEW |
| pg_catalog | pg_stat_progress_analyze | VIEW |
| pg_catalog | pg_stat_progress_basebackup | VIEW |
| pg_catalog | pg_stat_progress_cluster | VIEW |
| pg_catalog | pg_stat_progress_copy | VIEW |
| pg_catalog | pg_stat_progress_create_index | VIEW |
| pg_catalog | pg_stat_progress_vacuum | VIEW |
| pg_catalog | pg_stat_replication | VIEW |
| pg_catalog | pg_stat_replication_slots | VIEW |
| pg_catalog | pg_stat_slru | VIEW |
| pg_catalog | pg_stat_ssl | VIEW |
| pg_catalog | pg_stat_subscription | VIEW |
| pg_catalog | pg_stat_sys_indexes | VIEW |
| pg_catalog | pg_stat_sys_tables | VIEW |
| pg_catalog | pg_stat_user_functions | VIEW |
| pg_catalog | pg_stat_user_indexes | VIEW |
| pg_catalog | pg_stat_user_tables | VIEW |
| pg_catalog | pg_stat_wal | VIEW |
| pg_catalog | pg_stat_wal_receiver | VIEW |
| pg_catalog | pg_stat_xact_all_tables | VIEW |
| pg_catalog | pg_stat_xact_sys_tables | VIEW |
| pg_catalog | pg_stat_xact_user_functions | VIEW |
| pg_catalog | pg_stat_xact_user_tables | VIEW |
| pg_catalog | pg_statio_all_indexes | VIEW |
| pg_catalog | pg_statio_all_sequences | VIEW |
| pg_catalog | pg_statio_all_tables | VIEW |
| pg_catalog | pg_statio_sys_indexes | VIEW |
| pg_catalog | pg_statio_sys_sequences | VIEW |
| pg_catalog | pg_statio_sys_tables | VIEW |
| pg_catalog | pg_statio_user_indexes | VIEW |
| pg_catalog | pg_statio_user_sequences | VIEW |
| pg_catalog | pg_statio_user_tables | VIEW |
| pg_catalog | pg_statistic | BASE TABLE |
| pg_catalog | pg_statistic_ext | BASE TABLE |
| pg_catalog | pg_statistic_ext_data | BASE TABLE |
| pg_catalog | pg_stats | VIEW |
| pg_catalog | pg_stats_ext | VIEW |
| pg_catalog | pg_stats_ext_exprs | VIEW |
| pg_catalog | pg_subscription | BASE TABLE |
| pg_catalog | pg_subscription_rel | BASE TABLE |
| pg_catalog | pg_tables | VIEW |
| pg_catalog | pg_tablespace | BASE TABLE |
| pg_catalog | pg_timezone_abbrevs | VIEW |
| pg_catalog | pg_timezone_names | VIEW |
| pg_catalog | pg_transform | BASE TABLE |
| pg_catalog | pg_trigger | BASE TABLE |
| pg_catalog | pg_ts_config | BASE TABLE |
| pg_catalog | pg_ts_config_map | BASE TABLE |
| pg_catalog | pg_ts_dict | BASE TABLE |
| pg_catalog | pg_ts_parser | BASE TABLE |
| pg_catalog | pg_ts_template | BASE TABLE |
| pg_catalog | pg_type | BASE TABLE |
| pg_catalog | pg_user | VIEW |
| pg_catalog | pg_user_mapping | BASE TABLE |
| pg_catalog | pg_user_mappings | VIEW |
| pg_catalog | pg_views | VIEW |
| public | advisor | BASE TABLE |
| public | classroom | BASE TABLE |
| public | course | BASE TABLE |
| public | department | BASE TABLE |
| public | flights | BASE TABLE |
| public | instructor | BASE TABLE |
| public | myemptytable | BASE TABLE |
| public | otherstudents | BASE TABLE |
| public | prereq | BASE TABLE |
| public | sales | BASE TABLE |
| public | section | BASE TABLE |
| public | seminars | BASE TABLE |
| public | student | BASE TABLE |
| public | takes | BASE TABLE |
| public | teaches | BASE TABLE |
| public | time_slot | BASE TABLE |
|
|
| table_name | column_name | ordinal_position | data_type |
|---|---|---|---|
| sales | year | 1 | integer |
| sales | month | 2 | integer |
| sales | totsales | 3 | numeric |
| section | course_id | 1 | character varying |
| section | sec_id | 2 | character varying |
| section | semester | 3 | character varying |
| section | year | 4 | numeric |
| section | building | 5 | character varying |
| section | room_number | 6 | character varying |
| section | time_slot_id | 7 | character varying |
| seminars | title | 1 | character varying |
| seminars | presenter | 2 | character varying |
| seminars | semdate | 3 | timestamp without time zone |
| seminars | building | 4 | character varying |
| seminars | room_number | 5 | character varying |
| seminars | organizing_dept | 6 | character varying |
| student | id | 1 | character varying |
| student | name | 2 | character varying |
| student | dept_name | 3 | character varying |
| student | tot_cred | 4 | numeric |
More on constraints
foreign keys
-
for foreign keys we can specify what action to take if the referenced table is updated
- for deletions
ON DELETE - for update
ON UPDATE
- for deletions
-
options
SET NULL- set fk columns toNULLRESTRICT- disallow deletion / updates for tuples that referenced-
CASCADE- for deletion: delete referencing rows
- for update: update the values of referencing rows
|
|
| CREATE TABLE |
|---|
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
- persons that reference address
|
|
| CREATE TABLE |
|---|
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
| INSERT 0 1 |
|
|
|
|
| ALTER TABLE |
|
|
| DELETE 1 |
|
|
| name | addrid |
|---|---|
| C | 2 |
| D | 4 |
| E | 4 |
| F | 4 |
|
|
| UPDATE 1 |
|
|
| name | addrid |
|---|---|
| C | 2 |
| D | |
| E | |
| F |
CHECK constraints
- check boolean condition over the values of columns (from this table!)
|
|
| id | city | zip |
|---|---|---|
| 1 | NY | 15555 |
|
|
| ALTER TABLE |
- violates the constraint since
15555does not start with60
|
|
Updates (DML)
transactions
-
allow us to group SQL statements into atomic
- either all will be executed or none
- and current transactions cannot interact (later when we talk concurrency control)
- transaction end if you run a
COMMITorABORT - the database will abort transactions if a statement throws an error
|
|
| BEGIN |
|---|
| INSERT 0 1 |
|
|
| id | city | zip |
|---|---|---|
| 2 | Chicago | 60612 |
| 3 | Chicago | 60645 |
| 5 | Evanston | 60555 |
advanced update statement
insert query results
INSERT INTO ... SELECT
|
|
| INSERT 0 11 |
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 19991 | Brandt | History | 80 |
| 23121 | Chavez | Finance | 110 |
| 44553 | Peltier | Physics | 56 |
| 45678 | Levy | Physics | 46 |
| 54321 | Williams | Comp. Sci. | 54 |
| 55739 | Sanchez | Music | 38 |
| 70557 | Snow | Physics | 0 |
| 76543 | Brown | Comp. Sci. | 58 |
| 76653 | Aoi | Elec. Eng. | 60 |
| 98765 | Bourikas | Elec. Eng. | 98 |
| 98988 | Tanaka | Biology | 120 |
| AB199 | Brandt | History | 80 |
| AB231 | Chavez | History | 110 |
| AB445 | Peltier | History | 56 |
| AB456 | Levy | History | 46 |
| AB543 | Williams | History | 54 |
| AB557 | Sanchez | History | 38 |
| AB705 | Snow | History | 0 |
| AB765 | Brown | History | 58 |
| AB766 | Aoi | History | 60 |
| AB987 | Bourikas | History | 98 |
| AB989 | Tanaka | History | 120 |
update / delete with nested subqueries
- can use nested subqueries in
WHEREof delete or update
|
|
| count | dept_name |
|---|---|
| 3 | Physics |
| 1 | Biology |
| 2 | Elec. Eng. |
| 1 | Finance |
| 2 | Comp. Sci. |
| 12 | History |
| 1 | Music |
|
|
| DELETE 7 |
|
|
| id | name | dept_name | tot_cred |
|---|---|---|---|
| 19991 | Brandt | History | 80 |
| 44553 | Peltier | Physics | 56 |
| 45678 | Levy | Physics | 46 |
| 70557 | Snow | Physics | 0 |
| AB199 | Brandt | History | 80 |
| AB231 | Chavez | History | 110 |
| AB445 | Peltier | History | 56 |
| AB456 | Levy | History | 46 |
| AB543 | Williams | History | 54 |
| AB557 | Sanchez | History | 38 |
| AB705 | Snow | History | 0 |
| AB765 | Brown | History | 58 |
| AB766 | Aoi | History | 60 |
| AB987 | Bourikas | History | 98 |
| AB989 | Tanaka | History | 120 |
Lecture
exam topics review and questions
Access control
|
|
| REVOKE |
|---|
| DROP ROLE |
| CREATE ROLE |
|
|
| GRANT |
|
|
| GRANT |
|
|
| CREATE VIEW |
-
roles
1 2 3 4CREATE ROLE hr; GRANT SELECT on studentstats TO hr; GRANT hr TO testuser; REVOKE ALL ON student FROM testuser;GRANT GRANT ROLE REVOKE
User defined types and functions
UDT = user-defined types
- define new types
-
in postgres use C and SQL to register the new type and its functions: https://www.postgresql.org/docs/current/xtypes.html
- input: take string and return binary representation
- output: take binary and return string representation
- send/receive: serialize / deserialize for network transfer
UDF = user-defined functions and operators
- can be written in PL like C, Python, …
Procedural extensions
- https://www.postgresql.org/docs/current/plpgsql.html
- in Postgres there is procedural extension for writing SQL + imperative code PL/PGSQL
|
|
| CREATE FUNCTION |
|
|
| get_num_students |
|---|
| 16 |
|
|
| CREATE FUNCTION |
|
|
| name | dept_name | get_num_students |
|---|---|---|
| Brandt | History | 13 |
| Peltier | Physics | 3 |
| Levy | Physics | 3 |
| Snow | Physics | 3 |
| Brandt | History | 13 |
| Chavez | History | 13 |
| Peltier | History | 13 |
| Levy | History | 13 |
| Williams | History | 13 |
| Sanchez | History | 13 |
| Snow | History | 13 |
| Brown | History | 13 |
| Aoi | History | 13 |
| Bourikas | History | 13 |
| Tanaka | History | 13 |
| test | History | 13 |
|
|
| CREATE FUNCTION |
|
|
| plus_one |
|---|
| 2 |
control flow and iteration
conditional control flow
|
|
| CREATE FUNCTION |
|
|
| add_one_if_large_else_add_two |
|---|
| 5 |
| add_one_if_large_else_add_two |
| 201 |
looping
|
|
| CREATE FUNCTION |
|
|
| add_one_hun |
|---|
| 200 |
looping through query results
https://www.postgresql.org/docs/current/plpgsql-control-structures.html#PLPGSQL-RECORDS-ITERATING
|
|
| CREATE FUNCTION |
|
|
| another_cnt |
|---|
| 13 |
table returning functions
|
|
| i |
|---|
| 1 |
| 2 |
| 3 |
| 4 |
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
| 10 |
Lecture
Accessing databases from programming languages
Java
Lecture
Triggers
- triggers are special functions that are executed when a certain action is performed on a table
- in Postgres you first have to define the trigger function and then you can create a trigger
postgres trigger creation syntax
|
|
trigger function
- returns value of type trigger
|
|
trigger example: implement history tables with triggers
- do not loose the history of the table (keep old version)
|
|
| CREATE TABLE |
|---|
| INSERT 0 3 |
| CREATE VIEW |
| CREATE TABLE |
|
|
| a | b | t_begin |
|---|---|---|
| 1 | 1 | 2022-10-19 15:31:29.584735 |
| 2 | 2 | 2022-10-19 15:31:29.584735 |
| 3 | 3 | 2022-10-19 15:31:29.584735 |
|
|
| a | b | t_begin | t_end |
|
|
| CREATE FUNCTION |
|
|
| CREATE TRIGGER |
|
|
| INSERT 0 1 |
|---|
| DELETE 1 |
|
|
| a | b | t_begin | t_end |
|---|---|---|---|
| 1 | 1 | 2022-10-19 15:35:20.330632 | 2022-10-19 15:35:20.339711 |
|
|
| DELETE 1 |
|
|
| INSERT 0 2 |
|
|
| a | b | t_begin |
|---|---|---|
| 3 | 3 | 2022-10-19 15:31:29.584735 |
| 4 | 2 | 2022-10-19 15:38:07.803667 |
| 5 | 3 | 2022-10-19 15:38:07.803667 |
|
|
| DELETE 2 |
|
|
| a | b | t_begin | t_end |
|---|---|---|---|
| 2 | 2 | 2022-10-19 15:31:29.584735 | 2022-10-19 15:36:48.183113 |
| 1 | 1 | 2022-10-19 15:35:20.330632 | 2022-10-19 15:35:20.339711 |
| 4 | 2 | 2022-10-19 15:38:07.803667 | 2022-10-19 15:38:13.546615 |
| 5 | 3 | 2022-10-19 15:38:07.803667 | 2022-10-19 15:38:13.546615 |
- get data as of a certain time
|
|
| a | b |
|---|---|
| 1 | 1 |
| 2 | 2 |
- now updates
|
|
| CREATE FUNCTION |
|
|
| CREATE TRIGGER |
|
|
| INSERT 0 4 |
|
|
| a | b | t_begin |
|---|---|---|
| 3 | 3 | 2022-10-19 15:31:29.584735 |
| 5 | 5 | 2022-10-19 15:42:57.311625 |
| 6 | 6 | 2022-10-19 15:42:57.311625 |
| 7 | 1 | 2022-10-19 15:44:53.411487 |
| 8 | 2 | 2022-10-19 15:44:53.411487 |
|
|
| UPDATE 2 |
|
|
| a | b | t_begin | t_end |
|---|---|---|---|
| 1 | 1 | 2022-10-19 15:35:20.330632 | 2022-10-19 15:35:20.339711 |
| 2 | 2 | 2022-10-19 15:31:29.584735 | 2022-10-19 15:36:48.183113 |
| 4 | 2 | 2022-10-19 15:38:07.803667 | 2022-10-19 15:38:13.546615 |
| 5 | 3 | 2022-10-19 15:38:07.803667 | 2022-10-19 15:38:13.546615 |
| 7 | 7 | 2022-10-19 15:42:57.311625 | 2022-10-19 15:44:53.392018 |
| 8 | 8 | 2022-10-19 15:42:57.311625 | 2022-10-19 15:44:53.392018 |
| 7 | 1 | 2022-10-19 15:44:53.411487 | 2022-10-19 15:45:03.793728 |
| 8 | 2 | 2022-10-19 15:44:53.411487 | 2022-10-19 15:45:03.793728 |
|
|
| a | b |
|---|---|
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
ER-model
requirement analysis: music collection
- genres, albums, artists
-
We store information about songs
- Songs have a title
- Songs are written by one or more artists
- Songs can be on albums as tracks and appear with a particular track number
- Songs can have a genre
-
We store information about artists.
- Artists have a name
- Artists have a date of birth and optionally a date of death
-
We want to store information about albums.
- Albums have a release date
- Albums have a number of tracks which are songs and have additionally a track number and length
- Albums have artists playing on the album
- Albums are released by some publisher (typically record company)
- Albums have titles
Lecture
ER-model
Entities and relationships
students taking courses example

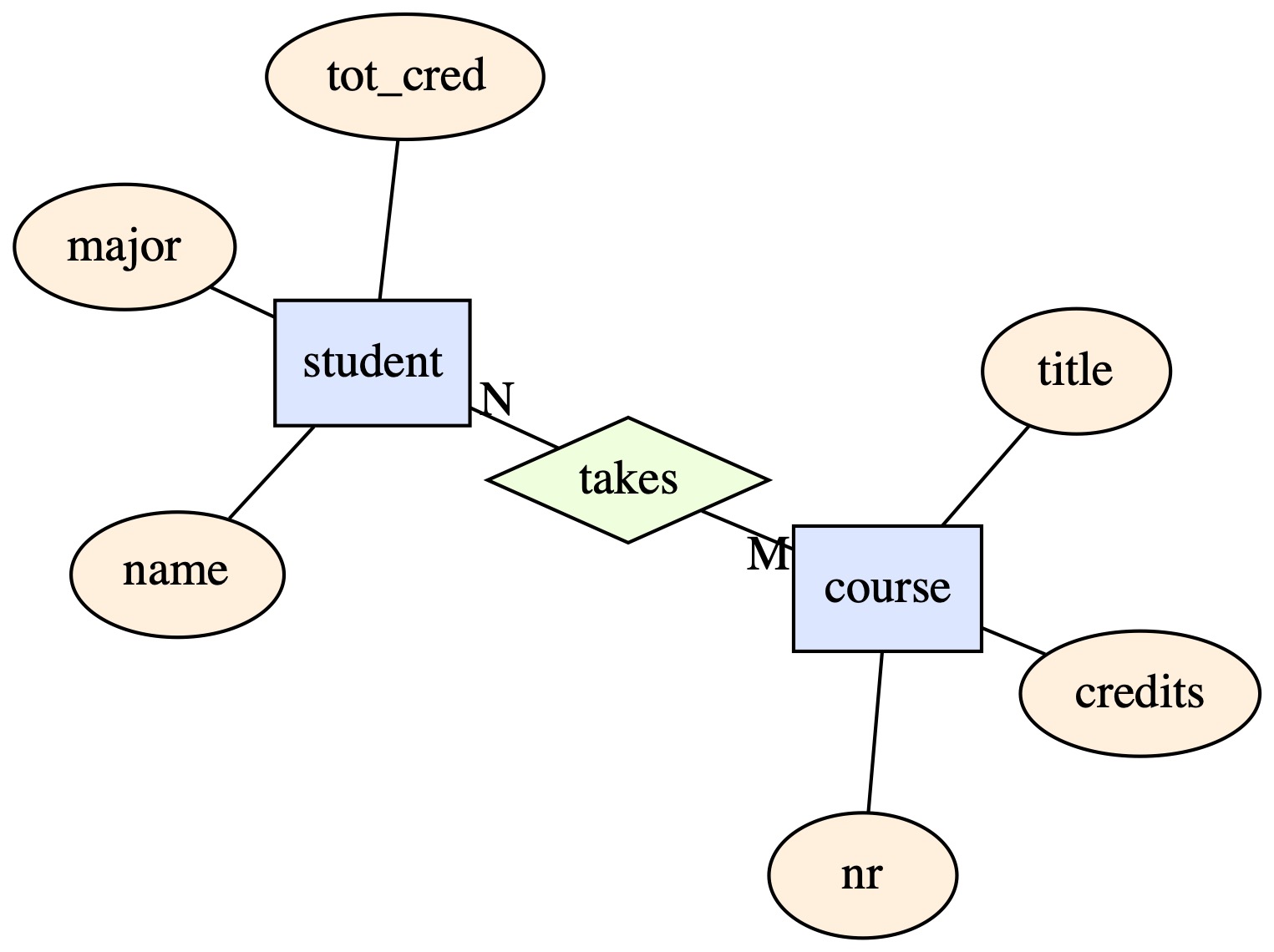
Examples
Music collection

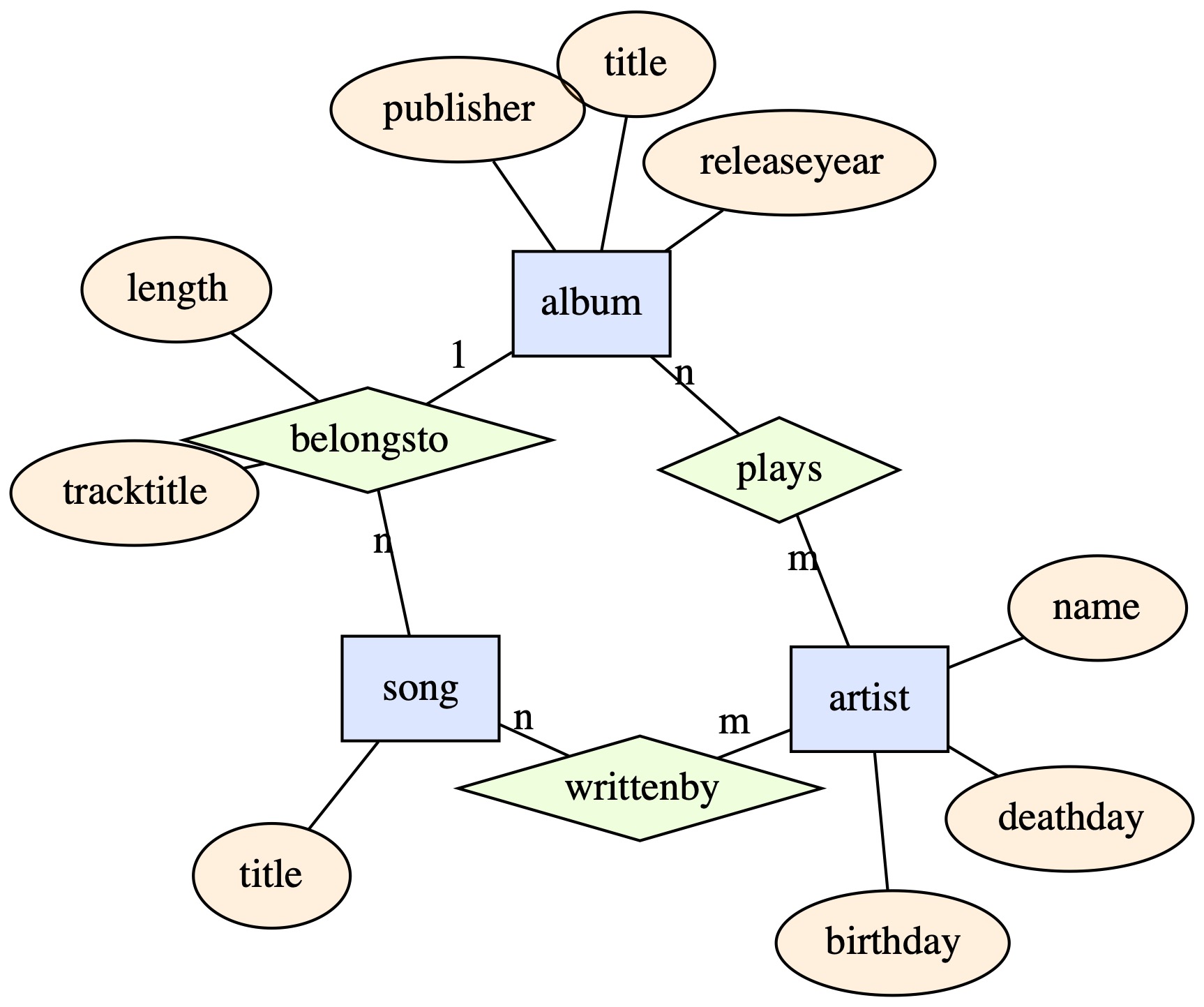
Lecture
Lecture
Lecture
LEFT OUTER JOIN for not exists checks
|
|
exam scaling
- grade = 0.25 * 100/85 * midterm score + …
Lecture
Lecture
Lecture
example of determining normal forms
2NF
- 1NF (always assumed)
- $$R = (A,B,C,D,E)$$
- $$F = \{ A \rightarrow E, BC \rightarrow D, C \rightarrow E \}$$
-
2NF
- candidate keys $$\{\{ A,B,C \}\}$$
- $$ABC^{+} = ABCDE$$
- non-prime = $$\{D,E\}$$
- counterexample: $$A \rightarrow E$$ is a dependency from part of a candidate key to a non-prime attribute
- this is not in 2NF
- $$R = (A,B,C,D,E)$$
- $$F = \{ A \rightarrow E, BC \rightarrow AD, C \rightarrow E \}$$
-
candidate keys $$\{\{ B,C \}\}$$
- non-prime = $$\{A,D,E\}$$
- counterexample: $$C \rightarrow E$$ is a dependency from part of a candidate key to a non-prime attribute
- this is in not 2NF
- $$R = (A,B,C,D,E)$$
- $$F = \{ A \rightarrow E, BC \rightarrow AD \}$$
-
candidate keys $$\{\{ B,C \}\}$$
- non-prime = $$\{A,D,E\}$$
- counterexample: is a dependency from part of a candidate key to a non-prime attribute
- this is in 2NF
3NF
- $$R = (A,B,C,D,E)$$
- $$F = \{ A \rightarrow E, BC \rightarrow AD \}$$
-
candidate keys $$\{\{ B,C \}\}$$
- non-prime = $$\{A,D,E\}$$
- counterexample: is a dependency from part of a candidate key to a non-prime attribute
- this is in 2NF
- $$A \rightarrow E$$ is neither trivial, nor is A a superkey, nor is E part of a candidate key!
- this is not in 3NF
- just an exercise: $$BC \rightarrow AD$$ ok, BC is a superkey
- $$BC \rightarrow B$$ - trivial and BC is a superkey $$BC^{+} = BCADE$$
BCNF
- same as first two options for 3NF (exploit that)
attribute closures and canonical cover
- $$F = \{ A \rightarrow BCD, B \rightarrow A, C \rightarrow D \}$$
- $$F^{+} = \{ AB \rightarrow B, A \rightarrow D, \ldots \}$$
- attribute closure $$A^{+} = ABCD$$
-
$$F^{C} = \{ A \rightarrow BCD, B \rightarrow A, C \rightarrow D \}$$
- find extraneous attributes in RHS, LHS
-
is $$D$$ extraneous in $$A \rightarrow BCD$$
-
$$F' = \{ A \rightarrow BC, B \rightarrow A, C \rightarrow D \}$$
- attribute closure $$A^{+}$$ = $$ABCD$$
-
-
$$F^{C} = \{ A \rightarrow BC, B \rightarrow A, C \rightarrow D \}$$
- is $$B$$ extraneous in $$A \rightarrow BC$$
-
$$F' = \{ A \rightarrow C, B \rightarrow A, C \rightarrow D \}$$
- attribute closure $$A^{+}$$ = $$ACD$$ (not extraneous)
- is $$C$$ extraneous in $$A \rightarrow BC$$?
-
$$F' = \{ A \rightarrow B, B \rightarrow A, C \rightarrow D \}$$
- attribute closure $$A^{+}$$ = $$AB$$ (not extraneous)
- $$F^{C} = \{ A \rightarrow BC, B \rightarrow A, C \rightarrow D \}$$ is the final result
decomposition into 3NF
Let's use $$F^{C} = \{ A \rightarrow BC, B \rightarrow A, C \rightarrow D \}$$ as an example.
- start with empty set of fragments $$\{\}$$
- $$A \rightarrow BC$$ - $$R_1 = (A,B,C)$$
- $$B \rightarrow A$$ - we already have $$R_1$$
- $$C \rightarrow D$$ - $$R_2 = (C,D)$$
- we already have $$R_1$$ containing candidate key $$A$$
- no contained fragments
- final decomposed result is $$\{R_1, R_2\}$$